近年、Transformer をベースとした大規模言語モデル(LLM: Large Language Model)が目覚ましい成果を上げる一方で、長いコンテキストを扱う際の計算コストやメモリ効率の課題から、状態空間モデル(SSM: State Space Model)や RNN(Recurrent Neural Network)、線形アテンションといった代替アーキテクチャが次々と提案されています。
しかし、これらの新しいモデルたちは、それぞれ独自のアプローチや数式で語られることが多く、「結局のところ、本質的な違いは何なのか?」 という全体像が見えにくくなっているのが現状です。
今回紹介する論文では、このような複雑に絡み合ったシーケンスモデルの設計空間を、「メモリ(記憶)」という単一の概念を通して見事に整理しています。またそれだけでなく、そこから Transformer や RNN とは異なる新しいアーキテクチャを持つモデルを導き出しています。
紹介する論文
| 項目 | 内容 |
| 論文名 | It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization |
| 公開年 | 2025年 |
| URL | https://arxiv.org/abs/2504.13173 |
本記事の要約
Transformer や RNN などのシーケンスモデルを「連想メモリ」という統一的な視点で整理する Miras フレームワークを提案し、そこから導かれた新しいモデルが既存手法を上回る性能を示している。
ポイント
-
統一的な視点:
Transformer の自己注意も RNN の隠れ状態も、どちらも「連想メモリの読み書き」として捉えられることを示し、乱立するシーケンスモデルを4つの設計軸(メモリ形状・対応評価関数・学習規則・保持規則)で体系的に整理した論文です。 -
新しいモデルの提案:
Miras フレームワークの設計空間から Moneta・Yaad・Memora という3つの新しいモデルを構築し、深層メモリと呼ばれる多層構造を共通の基盤として採用しています。 -
実験結果:
次単語予測タスクにおいて、提案モデルは Transformer++ や Mamba2 などの既存手法と同等以上の性能を達成し、特にコンテキスト長のスケーリングで優れた傾向を示しています。
はじめに
時系列データやトークン列といった「順序を持つ情報」は、一般的にシーケンスデータと呼ばれます。
現在、このようなデータを扱うモデリング分野では、Transformer アーキテクチャが標準的な手法としてさまざまな用途で広く用いられています。
しかし、その優れた能力を持つ一方で、Transformer は入力長 $L$ に対して計算量が $O(L^2)$ と増大するため、非常に長いシーケンスを扱う際には計算コストが急激に増え、大きな課題となっています。
このような課題があるため、「より長いコンテキストを効率的に扱える線形計算量のリカレントモデル(Linear-RNN)」など、Transformer の弱点を補う新しいアプローチを目指す研究が進んでいます。
ChatGPT をはじめとした現在のモデルも「計算効率を高めるための工夫」は導入されていますが、「任意の長さの文章を安価かつ高精度で処理できる」という観点では、まだ十分に解決されているとは言えません。
こうした状況の中、本論文では、Transformer や RNN 系のモデルを、どちらも連想メモリ(Associative memory) として捉え直す Miras フレームワークを提案しています。
Miras フレームワークは、シーケンスモデルを「どんな形のメモリを持ち、どんな目的でそれを更新するか」という観点から整理したものです。さらにただ整理するだけでなく、作成したフレームワークの設計空間から、Moneta・Yaad・Memora という3つの新しいモデルを構築し、次単語予測のタスクで既存手法を上回る性能を示しています。
この流れを丁寧に見ていきましょう。
連想メモリの概念を通して Transformer と RNN を捉える
Transformer は高い性能を示す一方で、系列長 $L$ が長くなるほど自己注意の計算量とメモリ使用量が大きくなり、長い文脈を扱うのが苦手です。
一方で近年は、過去の情報を固定サイズの状態に圧縮して扱う RNN 系モデルも再び注目されています。
これら2つを単なる別系統のアーキテクチャとして並べるのではなく、「メモリをどう持ち、どう更新するか」の違いとして捉え直すこととします。
Transformer の基本動作
Transformer の自己注意(self-attention)のアーキテクチャの動作を復習しましょう。
自己注意は、各トークンが query・key・value という3種類のベクトルを作り、現在のトークンが「過去のどのトークンをどれくらい参照するか」を決める設計を持つモデルです。
このとき、各ベクトルは以下のように考えることができます。
- query:いま「何を知りたいか」
- key:その情報が「どこにありそうか」を示す手がかり
- value:実際に「取り出す情報」
自己注意機構とは、query と key の相性で参照先を決め、対応する value を集めて文脈を表現する仕組みです。
この仕組みを数式で整理します。
$N$ 個の入力列 $X \in \mathbb{R}^{N \times d_{in}}$ と、学習可能な行列 $W_Q, W_K, W_V \in \mathbb{R}^{d_{in} \times d_{in}}$ を用いると、これら3種類のベクトルは以下のように表されます。
$$
Q = XW_Q = \Bigg[\begin{array}{c} \mathbf{q}_1 \\ \vdots \\ \mathbf{q}_N \end{array}\Bigg],\quad
K = XW_K = \Bigg[\begin{array}{c} \mathbf{k}_1 \\ \vdots \\ \mathbf{k}_N \end{array}\Bigg],\quad
V = XW_V = \Bigg[\begin{array}{c} \mathbf{v}_1 \\ \vdots \\ \mathbf{v}_N \end{array}\Bigg]
$$
これらの query, key, value を用いると、各位置 $i$ に対する出力表現ベクトル $\mathbf{y}_i$ が得られます。 $\mathbf{y}_i$ は後段の予測にも用いられる表現であり、その位置の query $\mathbf{q}_i$ と、自分より前に現れたトークン(厳密には $j \le i$ の位置)から得られた key-value ペア $(\mathbf{k}_j, \mathbf{v}_j)$ を用いて、次式で計算されます。
$$
\mathbf{y}_i
=
\sum_{j=1}^{i}
\dfrac{\exp\!\left(\mathbf{q}_i^\top \mathbf{k}_j / \sqrt{d_{\text{in}}}\right)\, \mathbf{v}_j}
{\displaystyle\sum_{\ell=1}^{i}\exp\!\left(\mathbf{q}_i^\top \mathbf{k}_\ell / \sqrt{d_{\text{in}}}\right)}
$$
$\mathbf{q}_i^\top \mathbf{k}_j / \sqrt{d_{\text{in}}}$ の部分は、位置 $i$ と位置 $j$ の関連度を表します。値が大きいほど、位置 $j$ の情報が位置 $i$ で重要と判断されます(分母は正規化のためです)。
要するに自己注意は、query と key の類似度に基づいて参照の強さを決め、その重みで value を混ぜ合わせる演算ということになります。
ここで注目したいのは、各位置 $i$ が大きくなるほど、参照すべき過去も増えていくことです。これが Transformer の限界に関係しています。
次に、本論文の内容に沿って、この振る舞いをメモリという概念で捉え直します。
メモリ
記憶(Memory) という器を考えてみましょう。そこには次々に情報がたまっていきます。この器を $M$ と表します。
重要なのは、この記憶の器が毎時点で更新されていくことです。
$M$ は固定のものではなく、時刻に応じて変化する $M_t$ として表すのが自然です。すると、記憶は $M_0, M_1, M_2, \ldots$ のように更新されていくことになります。
Transformer のメモリ
Transformer の仕組みをメモリの言葉で言い換えてみましょう。
この見方では、query は「記憶への問い合わせ」でありメモリの外部にあるもの、そしてメモリ本体は「それまでに読んだ位置から作られた key-value ペアの集まり」だとみなせます。
時刻 $t$ まで読み終えた時点でのメモリを $M_t$ と書くと、Transformer のメモリの更新式は
$$
M_t = M_{t-1} \cup \{(k_t, v_t)\}
$$
のように定式化できます。 Transformer は、このメモリに蓄えられた key-value の対応をその都度参照して、必要な情報を取り出していると見ることができます。
具体例
対象文: 「太郎はりんごを買った。彼はそれを食べた」
以下では、助詞を省いて「太郎」「りんご」「買った」「彼」「それ」「食べた」の6トークンだけを考えます。
各トークンを左から順に読むたびに、自分自身を含むそれまでのメモリ $M_i$($j \le i$ の位置の key-value ペア)を参照し、新たな key-value ペアがメモリに追加されます。
1. 「太郎」を読んだ直後
- 参照: 自分自身のみがメモリに存在するため、$(k_{\text{太郎}}, v_{\text{太郎}})$ を参照します(自己参照)。
- メモリ状態:
$$
M_1 = \{(k_{\text{太郎}}, v_{\text{太郎}})\}
$$
2. 「りんご」を読んだ直後
- 参照: $M_2$ の中から自分自身と「太郎」を参照できますが、ここでは特に強い関係はありません。
- メモリ状態:
$$
M_2 = \{(k_{\text{太郎}}, v_{\text{太郎}}),\ (k_{\text{りんご}}, v_{\text{りんご}})\}
$$
3. 「買った」を読んだ直後
- 参照: $M_3$ の中から自分自身と「太郎」「りんご」を参照します。「買った」の主語と目的語として、両方がある程度参照されます。
- メモリ状態:
$$
M_3 = \{(k_{\text{太郎}}, v_{\text{太郎}}),\ (k_{\text{りんご}}, v_{\text{りんご}}),\ (k_{\text{買った}}, v_{\text{買った}})\}
$$
4. 「彼」を読んだ直後
- 参照: $M_4$ の中から「彼」が誰を指すかを探します。$(k_{\text{太郎}}, v_{\text{太郎}})$ が特に強く参照され、「彼」は「太郎」と結びつきます。
- メモリ状態:
$$
M_4 = \{(k_{\text{太郎}}, v_{\text{太郎}}),\ (k_{\text{りんご}}, v_{\text{りんご}}),\ (k_{\text{買った}}, v_{\text{買った}}),\ (k_{\text{彼}}, v_{\text{彼}})\}
$$
5. 「それ」を読んだ直後
- 参照: $M_5$ の中から「それ」が何を指すかを探します。$(k_{\text{りんご}}, v_{\text{りんご}})$ が特に強く参照され、「それ」は「りんご」と結びつきます。
- メモリ状態:
$$
M_5 = \{(k_{\text{太郎}}, v_{\text{太郎}}),\ (k_{\text{りんご}}, v_{\text{りんご}}),\ (k_{\text{買った}}, v_{\text{買った}}),\ (k_{\text{彼}}, v_{\text{彼}}),\ (k_{\text{それ}}, v_{\text{それ}})\}
$$
6. 「食べた」を読んだ直後
- 参照: $M_6$ の中から、すでに結びついた「彼(=太郎)」や「それ(=りんご)」などを参照し、「太郎がりんごを食べた」という意味がまとまります。
- メモリ状態:
$$
\begin{aligned}
M_6 = \{&(k_{\text{太郎}}, v_{\text{太郎}}),\ (k_{\text{りんご}}, v_{\text{りんご}}),\ (k_{\text{買った}}, v_{\text{買った}}), \\
&(k_{\text{彼}}, v_{\text{彼}}),\ (k_{\text{それ}}, v_{\text{それ}}),\ (k_{\text{食べた}}, v_{\text{食べた}})\}
\end{aligned}
$$
ポイント
どのステップでも、モデルはその時点で利用可能なメモリ $M_i$(自分自身を含む $j \le i$ の key-value ペア)を参照しています。
特に「彼」や「それ」のように、文脈との対応が重要な語では、メモリの中から関係の深いペアが強く参照されることになります。
上の具体例のように Transformer におけるメモリは「key-value のペアをどんどん貯めていく」仕様になっています。
この意味で Transformer は、過去トークンから得た $(\mathbf{k}_j, \mathbf{v}_j)$ の組をそのまま保持し、必要なときに参照する保存型メモリ(非圧縮メモリ)だと見なせます。なお、Miras 論文の Table 1 では、Transformer は nonparametric な matrix-memory として整理されています。
この見方をすると、Transformer の強みと弱みが同時に見えてきます。
過去の情報を key-value ペアの集合としてメモリ $M_t$ にそのまま追加していく方式(KV cache)は、柔軟な参照ができる一方で、文脈が長くなるほど $M_t$ のサイズが増大し、計算の負担も重くなります。
つまり、「読んだものをすべて $M_t$ に残しておく」という戦略は、長文処理において非効率を招くことになってしまっています。
これが Transformer のボトルネックです。
RNN 系モデルの種類
RNN(Recurrent Neural Network, 再帰型ニューラルネットワーク)は、系列データ(時系列や文章など)のように、順番に並んだ情報を扱うためのニューラルネットワークの一種です。
より踏み込んで言えば 「直前までの計算結果(隠れ状態)」を持ち運びながら、入力が進むごとにその状態を更新していく という設計思想を持ったモデルになります。
RNN 系モデルは、一時代を築いた非線形(ゲート付き)RNN(LSTM: Long Short-Term Memory や GRU: Gated Recurrent Unit など)と、ここ数年で急速に注目されてきた線形 RNN(RetNet, RWKV, Mamba など)の2つの流れに大別できます。
| 種別 | 代表例 | 長所 | 短所 |
| 非線形(ゲート付き)RNN | LSTM, GRU | sigmoid / tanh のゲートで「何を保持し何を忘れるか」を柔軟に制御でき、状態追跡の表現力が高い | 時刻 t の状態が出るまで次ステップを計算できず、学習時の並列化が難しい。大規模学習に不向き |
| 線形RNN | RetNet, RWKV, LRU, Mamba | 更新が「線形変換+加算」に近い形なので、並列スキャン等を使って系列全体を高速に学習できる | 単純な加算型だと記憶が飽和しやすい。そのため、古い記憶を必要に応じて上書き・調整できるような、より高度な更新則や豊かなメモリアーキテクチャの導入が課題 |
このように RNN 系の発展は、表現力・記憶容量・学習の並列化可能性をどう両立させるかをめぐる試行錯誤として見ることができます。
RNN 系のメモリ
RNN 系と Transformer をメモリの視点で見ると、両者の違いは「記憶の持ち方」にあります。 Transformer は各トークンの key-value ペアを外部メモリ(KV キャッシュ)にそのまま追加し続けるのに対し、RNN 系はそれらの情報を要約し、固定サイズの内部状態(隠れ状態やメモリ行列)として保持します。言い換えれば、RNN 系は過去の $(k_j, v_j)$ 全体を直接残すのではなく、圧縮・集約(compress)したメモリ $M_t$ として持ち運ぶ方式になります(その分メモリ効率が良いということになります)。
時刻 $t$ まで読み終えた時点でのメモリを $M_t$ と書くと、RNN 系の更新は一般に
$$
M_t = \mathrm{Update}(M_{t-1}, k_t, v_t)
$$
のように表せます。
Miras 論文では、この更新を「現在の key-value を見て、連想記憶を書き換える操作」と捉えます。
特に Mamba・RetNet・GLA など Hebbian 系の線形 RNN モデルでは、共通して次のような更新式が用いられています(DeltaNet や Gated DeltaNet は delta rule に基づく別の更新方式を採用しています)。
$$
M_t = \underbrace{A_t * M_{t-1}}_{\text{過去の情報の保持}} + \underbrace{v_t k_t^\top}_{\text{新しい情報の書き込み}}
$$
ここで、第1項 $A_t * M_{t-1}$ では1ステップ前のメモリ状態に減衰処理を施しており、過去の記憶をどれだけ現在のステップに引き継ぐかを決定します。第2項 $v_t k_t^\top$ は現在時刻 $t$ の入力から得られたキーとバリューの外積であり、新たな関連性をメモリに加算(記憶)します。
$v_t k_t^\top$ の計算結果は行列
$v_t k_t^\top$ は「列ベクトル × 行ベクトル」の行列積であり、内積(スカラーになる $k_t^\top v_t$ とは逆順)とは異なり、結果は $d \times d$ の行列になります。行列の $(i, j)$ 成分には $v_{t,i}\, k_{t,j}$ が格納され、「このバリュー成分とこのキー成分がどれだけ同時に大きかったか」を記録します。これはニューラルネットワークの学習則である Hebb の法則(”同時発火するニューロン同士は結びつきが強くなる”という法則)に対応しており、こうしたキーとバリューの関連性をメモリに書き込んでいます。
重要なのは、Transformer のようにメモリ項目が増えていく(追加されていく)のではなく、同じ大きさの器 $M_t$ の中身が毎回更新されることです。
具体例
対象文: 「太郎はりんごを買った。彼はそれを食べた」
以下では、Transformer と同じく「太郎」「りんご」「買った」「彼」「それ」「食べた」の6トークンだけを考えます。
RNN 系では、各トークンを左から順に読むたびに、モデルは前時刻のメモリを参照し、その内容を圧縮し直して次の状態に更新します。
分かりやすさのため、その時点の圧縮状態を $\operatorname{compress}(\cdot)$ と書きます。
1. 「太郎」を読んだ直後
- 参照: まだ過去のトークンがないため、参照は行われません。
- 更新: メモリは「現在の話題は太郎」という状態に更新されます。
$$
M_1 = \operatorname{compress}(\text{太郎})
$$
2. 「りんご」を読んだ直後
- 参照: $M_1$ に圧縮された「太郎」の情報を引き継ぎます。
- 更新: メモリは「太郎」と「りんご」をまとめて保持する状態になります。
$$
M_2 = \operatorname{compress}(\text{太郎}, \text{りんご})
$$
3. 「買った」を読んだ直後
- 参照: $M_2$ に圧縮された主語・目的語の情報を使います。
- 更新: メモリは「太郎がりんごを買った」という出来事を要約した状態になります。
$$
M_3 = \operatorname{compress}(\text{太郎がりんごを買った})
$$
4. 「彼」を読んだ直後
- 参照: $M_3$ に保持された出来事と話題の情報を使って、「彼」が「太郎」を指すと解釈します。
- 更新: メモリは照応関係も折り込んだ状態に更新されます。
$$
M_4 = \operatorname{compress}(\text{太郎がりんごを買った},\ \text{彼}=\text{太郎})
$$
5. 「それ」を読んだ直後
- 参照: $M_4$ に圧縮された文脈を使って、「それ」が「りんご」を指すと解釈します。
- 更新: メモリは照応関係をさらに反映した状態に更新されます。
$$
M_5 = \operatorname{compress}(\text{太郎がりんごを買った},\ \text{彼}=\text{太郎},\ \text{それ}=\text{りんご})
$$
6. 「食べた」を読んだ直後
- 参照: $M_5$ に要約された出来事と照応の情報を使います。
- 更新: メモリは「太郎がりんごを食べた」という新しい出来事まで含んだ状態になります。
$$
M_6 = \operatorname{compress}(\text{太郎がりんごを買った},\ \text{太郎がりんごを食べた})
$$
ポイント
RNN 系では各時点でメモリそのものが更新されます。
「彼」や「それ」の解釈に必要な情報も、個別の項目として残るのではなく、次の予測に必要な要約状態として内部に畳み込まれて保持されます(Transformer との違いがここにあります)。
上の具体例のように RNN 系におけるメモリは「過去の情報を毎回同じ器に書き直す」仕様になっています。
この意味で RNN 系は、過去トークンから得た key-value 対応を固定サイズ状態の中に圧縮して保持し、必要なときにその要約状態を通じて使う圧縮更新型メモリだと見なせます。
Transformer と違い、強みはメモリサイズが系列長に依存しないことです。弱みは重要な情報をうまく残せないと長距離依存が薄れやすいことです(こちらは Transformer が比較的得意な強みですね)。
メモリという概念を通じて、Transformer と RNN の違いが見えてきたと思います。
実はここで紹介したメモリはいずれも、本論文においてはベクトルや行列といった単純な構造を持つ「浅いメモリ(shallow memory)」として分類されています。
この「メモリ」という概念をさらに一般化し、より表現力の高い構造も含めて統一的に整理したものが Miras フレームワーク です。
Miras フレームワーク
ここまで見た Transformer の保存型メモリと、RNN 系の圧縮更新型メモリの違いを、共通の設計空間として整理したものが Miras フレームワークです。
Miras の見方では、シーケンスモデルの違いは単に「Transformer か RNN か」という分類ではなく、
どんなメモリを持ち、どんな基準で学習し、どれだけ保持し、どんな最適化で更新するか
という4つの設計軸の違いとして理解されます。
Miras フレームワーク:4つの設計軸
メモリアーキテクチャ(Memory Architecture) どんな器に記憶するか(モデル形状)
ベクトルや行列、集合のような浅いメモリ(shallow memory) や、MLP(Multi-Layer Perceptron: 多層パーセプトロン)などの深い非線形ネットワークをメモリ本体として持つ 深層メモリ(deep memory) まで、記憶を保持する入れ物の形を定めます。
対応評価関数(Attentional Bias) 何を基準に覚えるか(目的関数の設計)
$\ell_p$ 損失(例:$\ell_1$ / $\ell_2$ 損失)、内積類似度、Huber 損失($\ell_1$ と $\ell_2$ の間を柔軟に切り替えられる損失関数)といった評価指標を使い、key-value の対応関係をどんな基準で最適化・評価するかを決めます。
保持ゲート(Retention Gate) どれだけ過去を残すか(保持正則化の設計)
過去の記憶をどれだけ維持し、どれだけ忘れるかを制御します(役割としては LSTM の「忘却ゲート」に近いです)。
数式上は $\ell_2$ 正則化や KL ダイバージェンスのような「過去の状態から変化しすぎないようにする」保持項として働くことで、新しい情報の学習と古い記憶の維持のバランスを取ります。
メモリ学習アルゴリズム(Memory Algorithm) どんな方法で学習するか(最適化アルゴリズムの設計)
勾配降下法、モメンタム法、ニュートン法、ノンパラメトリック解などがあり、記憶をどのような手順で更新するかを定めます。同じ目的関数でも、どの学習アルゴリズムを選ぶかによって、更新の速さや安定性、記憶への反映のされ方が変わります。
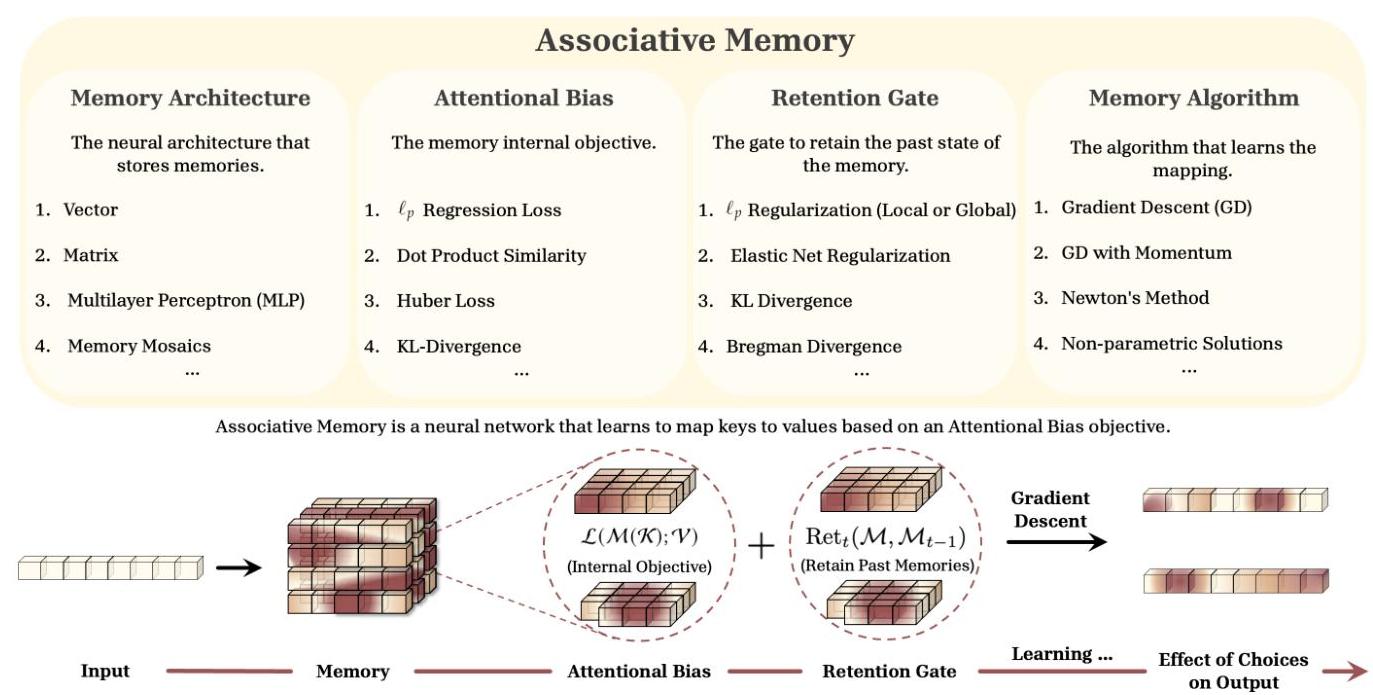
図1:Mirasフレームワークの概要(原論文 Figure 1)
Miras では、シーケンスモデルの本質を「メモリ」という観点から整理し、4つの設計軸(メモリアーキテクチャ・対応評価関数・保持ゲート・メモリ学習アルゴリズム)で体系化しています。
Miras フレームワークはこれら4つを設計軸として定式化されることになります。
この見方によって、さまざまな既存モデルを共通の理論的な傘の下で理解できるだけでなく、新しいアーキテクチャの設計空間も記述できるようになります。
つまり、Miras が既存モデルの整理図であるだけでなく、新しい系列モデルの設計図にもなっていることが分かります。
こうして開発されたのが、Moneta, Yaad, Memora という新たなシーケンスモデルになります。
次の節では、ここまで見てきた「メモリ」という見方を具体的に定式化し、Miras の背景にある考え方を整理します(読み飛ばしても問題ありません)。
Miras フレームワークに至る理論的背景
Transformer と RNN 系ではメモリの持ち方や更新の仕方は異なりますが、どちらも過去の情報を内部に保持しながら使うモデルとして捉えられます。このメモリをさらに抽象化し、連想記憶として捉え直すところから始まります。
以下では、まずメモリを key-value 対応を学ぶ写像として定義し、そこから対応評価関数や保持という考え方がどのように自然に現れるのかを見ていきます。
連想記憶 $\mathcal{M}$: key-value の対応関係
ここでは、メモリを単なるデータの保存場所ではなく、key から value を引き出す写像モデルとして捉えます。この観点に立つと、連想記憶は key の集合 $\mathcal{K}$ から value の集合 $\mathcal{V}$ への写像 $\mathcal{M}:\mathcal{K}\rightarrow\mathcal{V}$ とみなせます。そして、最も良い記憶(最適な写像)は次のように定義されます。
$$
\mathcal{M}^{\ast}
=
\arg\min_{\mathcal{M}}
\underbrace{
\mathcal{L}\bigl(
\overbrace{\mathcal{M}(\mathcal{K})}^{\text{記憶の中身/出力}},
\, \mathcal{V}
\bigr)
}_{\text{その良さの評価基準}}
$$
良いメモリ $\mathcal{M}^{\ast}$ とは、key-value の対応をうまく再現できるメモリということになります。この最適化の基準や方針を定めるのが $\mathcal{L}$ になります。
対応評価関数 $\mathcal{L}$:何をどう記憶するか
$\mathcal{L}$ は、メモリの出力 $\mathcal{M}(\mathcal{K})$ と実際の値 $\mathcal{V}$ とのずれを測る関数です。ただし、これは単なる誤差の測り方ではなく、どういったタイプの損失関数(内積類似度、$\ell_p$ 損失、Huber 損失)を使うのかによって、メモリ$\mathcal{M}$が重視する対応関係は変わります。
この意味で $\mathcal{L}$ は、key-value の対応をどの尺度で評価し、どの対応を優先(bias)して記憶(attention)するかを決める役割を持ちます。このことから、論文では $\mathcal{L}$ を対応評価関数 (Attentional Bias) と呼んでいます。
メモリ $\mathcal{M}$ の具体的なパラメータを $W$ とすると、実際の最適化は時系列に沿って入力が来るたびに、この $W$ を逐次的に更新していく形で行われます。
$$
\ell(W;\mathbf{k}_t,\mathbf{v}_t) := \mathcal{L}\bigl(\mathcal{M}(W;\mathbf{k}_t),\, \mathbf{v}_t\bigr)
$$
この見方に立つと、系列モデルは文章を読み進めながら、その場で自分自身のメモリ(重み $W$)を学習し直しているモデルとして解釈できます。
最新トークンの学習と既存記憶の保持
この逐次的なメモリの更新を、最も素直に勾配降下法で記述すると次のようになります。
$$
W_t = W_{t-1} – \eta_t \nabla \ell(W_{t-1};\, \mathbf{k}_t, \mathbf{v}_t) \tag{1}
$$
論文ではこの更新を「新しいトークンから学ぶこと」と「直前の記憶状態から離れすぎないこと」のトレードオフとして読み直します。具体的には、上の更新式は次の最適化問題と等価(equivalent)になります。
$$
W_t = \arg\min_{W} \left\{
\underbrace{\left\langle W – W_{t-1},\, \nabla \ell(W_{t-1};\, \mathbf{k}_t, \mathbf{v}_t) \right\rangle}_{\text{新しいトークンからの学習}}
+ \underbrace{\frac{1}{2\eta_t}\|W – W_{t-1}\|_2^2}_{\text{過去の記憶の保持}}
\right\}\tag{2}
$$
この式の第1項は、現在の記憶状態 $W_{t-1}$ の周辺で最新トークンに対する損失を局所的に線形近似した項で、一方、第2項は前の状態 $W_{t-1}$ から急に動きすぎないようにする保持項です。
つまり、逐次更新は新しい情報を学ぶ力と既存の記憶を保つ力のバランスとして理解できます。
損失関数 $\ell(W)$ を $W_{t-1}$ の周りで1次のテイラー展開(線形近似)すると以下のようになります。
$$
\ell(W) \approx \ell(W_{t-1}) + \langle \nabla \ell(W_{t-1}), W – W_{t-1} \rangle
$$
ここで、右辺第1項の $\ell(W_{t-1})$ は $W$ に依存しない定数項です。そのため、$\arg\min_{W}$ を計算する際には最適化の結果に影響を与えず、式(2)の目的関数からは省略されています。
論文では式(2)の各項の見方をさらに一般化し、「学習項 + 保持項」 の形で表しています。
$$
W_t = \arg\min_{W \in \mathcal{W}}
\underbrace{\widetilde{\ell}_t(W;\, \mathbf{k}_t, \mathbf{v}_t)}_{\text{対応評価関数(Attentional Bias)}}
+ \underbrace{\mathrm{Ret}_t(W, W_{t-1})}_{\text{保持ゲート(Retention Gate)}}
$$
なお、保持項は、直前状態からの逸脱を抑える局所保持と、メモリ全体の大きさや安定性を制御する大域保持に分解できます。
$$
\mathrm{Ret}_t(W, W_{t-1})
=
\underbrace{\frac{1}{\eta_t} D_t(W, W_{t-1})}_{\text{局所保持}}
+ \underbrace{\frac{1}{\alpha_t} G_t(W)}_{\text{大域保持}}
$$
$D_t(W, W_{t-1})$ は過去の知識を維持するための局所的な保持項であり、$G_t(W)$ はメモリのサイズや安定性に関する大域的な保持項です。
この分解が Miras の4軸になる
ここまで数式で整理してきた各要素は、そのまま Miras フレームワークの4つの設計軸に対応しています。すなわち、「賢い連想記憶をいかに設計するか」という最適化問題を、4つの観点に分解して捉えるための設計言語となっています。
【Miras の4つの設計軸】
-
メモリ構造(Memory Structure)
パラメータ $W$ の表現形式や制約 $\mathcal{W}$。ベクトルなのか、行列なのか、MLP のような深いメモリなのかを決めます。 -
対応評価関数(Attentional Bias)
新しい情報を学ぶための学習項 $\widetilde{\ell}_t(W;\, \mathbf{k}_t, \mathbf{v}_t)$。どの対応をどの尺度で評価し、どの情報を優先して学ぶかを決めます。 -
保持ゲート(Retention Gate)
既存の記憶を保つための保持項 $\mathrm{Ret}_t(W, W_{t-1})$。直前状態からの逸脱を抑える局所保持 $D_t$ と、メモリ全体の安定性を制御する大域保持 $G_t$ で構成されます。 -
メモリ学習アルゴリズム(Memory Algorithm)
$\arg\min$ による最適化問題を解くための手法です。勾配降下法、モメンタム法、ニュートン法、ノンパラメトリック解などがここに入ります。
新しいアーキテクチャの設計(Moneta・Yaad・Memora)
Miras の興味深いところは、既存モデル(Transformer や RNN)を整理する記述言語にとどまらず、4つの設計軸の組合せを変えることで新しい系列モデルを系統的に導ける点にあります。論文では、この枠組みを用いて新しい系列モデルを提案しています。
共通のメモリアーキテクチャ:深層メモリ
論文で提案されている Moneta・Yaad・Memora という3つの新しいモデルは、対応評価関数や保持ゲートの設計を変えることでそれぞれ異なる性質を実現していますが、メモリアーキテクチャ(Memory Architecture)としては共通して「深層メモリ(Deep Memory)」を採用しています。
具体的には、以下のような2層の MLP(多層パーセプトロン)をメモリアーキテクチャとして用いています。
$$
\mathcal{M}(x) = x + \operatorname{LN}(W_1\sigma(W_2x))
$$
ここで、$\operatorname{LN}$ はレイヤー正規化で、活性化関数 $\sigma$ は $\operatorname{GELU}$ です。式から残差接続を使っている事も分かります。
深層メモリは、他の Transformer や RNN のような単なる行列の演算や key-value ペア集合単体で決まる浅いメモリ(Shallow Memory)とは異なり、小さなニューラルネットワークそのものをメモリとして機能させています。これにより複雑なパターンを記憶できるようになっています。
Miras から生まれた3つの新しいモデル
3モデルを4軸に分解すると、次のようになります。3者は共通して deep memory を使いながら、主に対応評価関数と保持ゲートの違いによって性格が分かれていることが分かります。
特異点抽出・強記憶型モデル
標準的な $\ell_2$ 損失といった二乗ノルム($\|\cdot\|_2$)に固定せず、対応評価関数(Attentional Bias)に $\ell_p$ ノルム($\|\cdot\|_p$)を採用し、保持ゲート(Retention Gate)に $\ell_q$ ノルム($\|\cdot\|_q$)を用いた一般化モデルです。
$\ell_{p}$ ノルムを用いた柔軟な更新ルールにより、大きな予測誤差を伴う入力に対してより強くメモリを書き換えるように設計が可能となります。論文では Moneta に $(p, q)=(3, 4)$ を採用しています。
-
メモリアーキテクチャ: 2層 MLP(深層メモリ)
-
対応評価関数: $\ell_p$ 損失
-
保持ゲート: $\ell_q$ ノルムおよび $\ell_2$ ノルムの併用
-
メモリ学習アルゴリズム: 勾配降下法(GD)
対応評価関数:
$$
\ell_p(W;\mathbf{k}_t,\mathbf{v}_t)=\|\mathcal{M}(W,\mathbf{k}_t)-\mathbf{v}_t\|_p^p
$$
保持ゲート(どちらも大域保持):
$$
\mathcal{R}_t(W)=\underbrace{\frac{1}{2(q-1)}\|W\|_q^2}_{\text{大域保持($\ell_q$ ノルム)}}+\underbrace{\frac{1}{\beta}\|W\|_2^2}_{\text{大域保持($\ell_2$ ノルム)}}
$$
メモリの書き込み式:
$$
\begin{align*}
A_t &= \alpha_t A_{t-1} – \eta_t \nabla \ell_p(W_{t-1}; \mathbf{k}_t, \mathbf{v}_t),\\[2ex]
W_t &= \frac{A_t}{\|A_t\|_q^{q-2}}
\end{align*}
$$
記憶保護・安定型モデル
対応評価関数には Huber 損失を採用し、保持ゲートには局所保持と大域保持を兼ねる $\ell_2$ 型の保持項を組み合わせたモデルです。 Huber 損失は、誤差が小さいときは $\ell_2$ 的に振る舞い、誤差が大きいときは $\ell_1$ 的に振る舞うような損失関数です。この切り替えが、極端なトークンの影響を受けにくい更新を実現します。
その結果 Yaad は、通常の入力には精密に適応しつつ、外れ値的なトークンや予期しない入力に対してはメモリ状態が急激に崩れにくい、ロバスト記憶寄りのモデルになっています。実験でも、保持を外したり、Huber 損失の一部を外すと性能が低下しており、このロバスト的な設計が実際に効いていることが示されています。
-
メモリアーキテクチャ: 2層 MLP(深層メモリ)
-
対応評価関数: Huber 損失
-
保持ゲート: $\ell_2$
-
メモリ学習アルゴリズム: 勾配降下法(GD)
対応評価関数:
$$
\widetilde{\ell}_t(W;\mathbf{k}_t,\mathbf{v}_t)=
\begin{cases}
\ell_2(W;\mathbf{k}_t,\mathbf{v}_t) & \|\mathcal{M}(W,\mathbf{k}_t)-\mathbf{v}_t\| \le \delta_t \\[1ex]
\delta_t \ell_1(W;\mathbf{k}_t,\mathbf{v}_t) & \text{otherwise}
\end{cases}
$$
保持ゲート(局所保持+大域保持):
$$
\mathrm{Ret}_t(W,W_{t-1})=\underbrace{\frac{1}{2\theta_t}\|W-W_{t-1}\|_F^2}_{\text{局所保持}}+\underbrace{\frac{1}{\beta_t}\|W\|_2^2}_{\text{大域保持}}
$$
メモリの書き込み式
$$
W_t = \alpha_t W_{t-1} –
\begin{cases}
\eta_t\, \nabla \ell_2(W_{t-1}; \mathbf{k}_t, \mathbf{v}_t) & \|\mathcal{M}(W_{t-1}, \mathbf{k}_t) – \mathbf{v}_t\| \le \delta_t \\[1ex]
\eta_t\, \delta_t\, \nabla \ell_1(W_{t-1}; \mathbf{k}_t, \mathbf{v}_t) & \text{otherwise}
\end{cases}
$$
確率的適応・分布推移型モデル
対応評価関数には標準的な $\ell_2$ 損失を採用し、保持ゲートには KL(Kullback-Leibler)ダイバージェンスに基づく局所保持と大域保持を組み合わせたモデルです。 Moneta や Yaad が主に誤差の測り方を拡張していたのに対し、Memora はメモリ状態をどのような空間で安定に保持するかに重点を置いた設計になっています。
更新式に $\log$ と $\operatorname{Softmax}$ が現れることで、メモリは各ステップで非負かつ正規化された確率分布的な表現へ戻されます。そのため、新しい情報を $\ell_2$ 的に学習しながらも、過去の記憶分布から急に飛びすぎないよう制御でき、長い系列でもメモリ状態が暴走しにくい安定志向のモデルとして解釈できます。
-
メモリアーキテクチャ: 2層 MLP(深層メモリ)
-
対応評価関数: $\ell_2$ 損失
-
保持ゲート: KL ダイバージェンス(過去の記憶からの逸脱を防ぐ) + シャノンエントロピー($W$の値の分布の極端な偏りを防ぐ)
-
メモリ学習アルゴリズム: 勾配降下法(GD)
対応評価関数:
$$
\ell_2(W;\mathbf{k}_t,\mathbf{v}_t)=\|\mathcal{M}(W,\mathbf{k}_t)-\mathbf{v}_t\|_2^2
$$
保持ゲート(局所保持+大域保持):
$$
\mathrm{Ret}_t(W,W_{t-1})
=
\underbrace{\frac{1}{\eta_t}\sum_{j,l}W_{jl}\log\frac{W_{jl}}{(W_{t-1})_{jl}}}_{\text{局所保持(KLダイバージェンス)}}
+
\underbrace{\frac{1}{\alpha_t}\sum_{j,l}W_{jl}\log W_{jl}}_{\text{大域保持(シャノンエントロピー)}}
$$
※前者が 前の記憶分布から離れすぎないための KL 保持、後者が 分布としての形を保つための大域保持 です。
メモリの書き込み式:
$$
W_t = \underbrace{\operatorname{Softmax}\!\left(\underbrace{\alpha_t \log(W_{t-1})}_{\text{直前の記憶の対数圧縮}} – \eta_t \nabla \ell_2(W_{t-1}; \mathbf{k}_t, \mathbf{v}_t)\right)}_{\text{安定した記憶空間に正規化}}
$$
実験結果
提案されたモデルの性能は実際どれほどのものなのでしょうか?
理論として魅力的でも、実際に既存モデルより強くなければ意味がありません。論文では Moneta・Yaad・Memora を、次単語予測や常識推論、長文コンテキストタスク(needle-in-a-haystack)で比較しています。
比較対象には Transformer 系だけでなく、RetNet、Mamba2、DeltaNet、TTT、Gated DeltaNet などの有力なモデルも含まれています。
ベンチマーク性能
まず重要なのは、Miras 系の変種が一部の特殊なタスクだけで良いのではなく、次単語予測や常識推論のような標準的ベンチマークでも強いことです。以下の表は、1.3B パラメータ(100B トークン学習)という大規模な設定における、主要なモデルの性能比較の結果になります(論文より一部を抜粋)。
評価には、次単語予測の性能を測る WikiText-103(Wiki.)や LAMBADA(LMB.)のほか、物理的な常識推論(PIQA)、文脈推論(HellaSwag / Hella.)、代名詞の照応解決(WinoGrande / Wino.)、科学の選択式問題(ARC-Easy / ARC-e)といった多様な常識推論タスクが用いられています。
| Model (1.3B params) | Wiki. (ppl ↓) | LMB. (ppl ↓) | PIQA (acc ↑) | Hella. (acc_n ↑) | Wino. (acc ↑) | ARC-e (acc ↑) |
| Transformer++ | 18.53 | 18.32 | 70.02 | 50.23 | 53.51 | 68.83 |
| RetNet | 19.08 | 17.27 | 70.07 | 49.16 | 54.14 | 67.34 |
| Mamba2 | 16.56 | 12.56 | 71.87 | 55.67 | 55.24 | 72.47 |
| DeltaNet | 17.71 | 16.88 | 70.72 | 50.93 | 53.35 | 68.47 |
| Gated DeltaNet | 16.42 | 12.17 | 72.25 | 55.76 | 57.45 | 71.21 |
| Samba† | 16.13 | 13.29 | 70.94 | 53.42 | 55.56 | 68.81 |
| Gated DeltaNet-H2† | 15.91 | 12.55 | 72.19 | 56.88 | 57.77 | 71.33 |
| Moneta (MIRAS) | 15.52 | 11.47 | 73.16 | 56.14 | 59.09 | 72.53 |
| Yaad (MIRAS) | 15.18 | 11.89 | 72.81 | 56.46 | 59.02 | 72.14 |
| Memora (MIRAS) | 15.90 | 12.04 | 73.10 | 55.99 | 57.36 | 71.55 |
perplexity(ppl)は低いほど良く、accuracy(acc)は高いほど良いスコアとなります。緑セルは各列の最良値を示します。†はハイブリッドモデル(高精度だが高コストなAttention層と、軽量な線形RNN層を交互に積むことで、両者の長所を組み合わせた構成)。
とくに中規模から大規模の設定では、多くのケースで既存の recurrent 系ベースラインを上回り、いくつかの設定では hybrid 系や Transformer 系に匹敵、あるいは優位な結果も示しています。
スケーリング則(モデル規模とコンテキスト長)
モデルの真価を測る上で欠かせないのが、「スケーリング(規模を大きくしたときの性能の変化)」 になります。論文内の実験(原論文 Figure 3)では、「C4データセット」という大規模なテキストデータを用いて、モデルのサイズや読み込む文章の長さを増やした際に、性能がどう向上するかが検証されています。
C4(Colossal Clean Crawled Corpus)は、Google が公開した大規模な英語テキストデータセットで、Web ページから収集したテキストをクリーニング・フィルタリングして構築されたものです。詳細は Hugging Face のデータセットページ を参照してください。
この検証は大きく3つの観点で行われ、論文の評価設定において Miras 系モデルがベースラインより良好なスケーリングを示しています。
1. 計算量(モデルサイズ)に対するスケーリング

計算量に対するスケーリング(論文 Figure 3 左より)
- 何を見ているか: モデルの学習に使った計算量(FLOPs: Floating Point Operations)に対して、モデルの言語予測性能(パープレキシティ:値が低いほど優秀)がどのように変化するか。
- 結果: 提案された3つのモデル(Moneta, Yaad, Memora)はすべて、同じ計算コスト(FLOPs)を与えられた条件において、既存のベースラインモデルよりも低いパープレキシティを達成。
- 意味: 提案手法は、計算資源をより効率的に使って高い性能を引き出せる、非常に 「コストパフォーマンスの高い」アーキテクチャ である。
2. コンテキスト長に対するスケーリング(小型モデル)

コンテキスト長に対するスケーリング・340M(論文 Figure 3 中央より)
- 何を見ているか: モデルのパラメータ数を 3.4億(340M) に固定した状態で、一度に処理する文章の長さ(コンテキスト長)を 2,000 トークン(2K)から 32,000 トークン(32K)まで徐々に伸ばしていった際の性能変化を見ている。
- 結果: 文章が長くなるにつれて、提案モデルは Mamba2 などの最新ベースラインモデルよりも優れた(より良い)軌跡を描いて性能が向上(または維持)した。
- 意味: 提案手法は、長い文章の文脈を失わずに処理する 「ロングコンテキスト処理」において優れている。
3. コンテキスト長に対するスケーリング(中型モデル)

コンテキスト長に対するスケーリング・760M(論文 Figure 3 右より)
- 何を見ているか: 中央のグラフと全く同じ検証を、よりサイズの大きい 7.6億(760M) パラメータのモデルで行ったもの※。
- 結果: モデルサイズを大きくしても、中央のグラフと同様に、提案モデルがコンテキスト長の増加に対してベースラインより優れたスケーリングを示した。
- 意味: 提案手法の「長い文章への強さ」が、特定の小さなモデルだけでなく、モデルを大きくしても一貫して発揮される(スケールする) 。
おわりに
本記事では、Miras論文で述べられている核心部分をまとめました。ここで取り上げた内容以外にも、細かな技術や数理的なテクニックが、Mirasフレームワークを用いた体系化の文脈で見事に整理されています。
Miras は、「Transformer の代替」をひとつ提示した論文というより、シーケンスモデルを設計するための共通言語を与えた論文だと言えます。今後は個々のモデル名を追いかけるよりも、どのメモリを使い、どの対応評価関数で学び、どのように保持ゲートを有し、どの更新ルールで最適化しているのかという観点で見ることで、モデル間の本質的な違いがずっと理解しやすくなることでしょう。
参照 URL
- Miras 論文: https://arxiv.org/abs/2504.13173
- RetNet: https://arxiv.org/abs/2307.08621
- Mamba2: https://arxiv.org/abs/2405.21060
- DeltaNet: https://arxiv.org/abs/2406.06484
- TTT: https://arxiv.org/abs/2407.04620
- Gated DeltaNet: https://arxiv.org/abs/2412.06464