
LLM を活用したマルチエージェントシステムは、財務分析や市場調査、ソフトウェア開発など、実際の現場でも導入が進んでいます。これまでの多くの設計は エージェント間の対話(会話パターン・役割分担・対話プロトコル)を軸にしており、「議論を深めれば品質も向上する」という前提に立っていました。
しかし、対話を重ねれば 本当に品質は上がるのでしょうか?
この問いに対して、設計の中心を「会話」から「検証」へと移したフレームワーク VMAO(Verified Multi-Agent Orchestration)を紹介します。
紹介する論文
| 項目 | 内容 |
| 論文名 | Verified Multi-Agent Orchestration: A Plan-Execute-Verify-Replan Framework for Complex Query Resolution |
| 公開年 | 2026 年 |
| URL | https://arxiv.org/abs/2603.11445 |
本記事の要約
マルチエージェント協調の中心を「会話」ではなく「検証」に置く VMAO フレームワークを提案。独立した検証器が各エージェントの結果を点検し、不足があれば計画を組み直すループ構造により、回答の網羅性とソース品質がともに向上した。
ポイント
- 新しい視点:
AutoGen や MetaGPT などが「エージェント間の通信パターン」を中心に据えていたのに対し、VMAO は「結果に対する独立な品質検査」をシステムの中核に置いた点が新しいです。 - 提案手法:
クエリをサブ質問の DAG に分解して並列実行し、独立した検証器が結果を評価して不足があれば計画を組み直す「Plan → Execute → Verify → Replan → Synthesize」の 5 フェーズループを採用しています。 - 実験結果:
市場調査クエリでの評価で、従来手法と比べ 網羅性(関連する観点をどれだけ漏らさず拾えているか)と ソース品質(回答がどれだけ確かな出典に基づいているか)がともに向上。リソース消費と引き換えに品質を押し上げることが確認されました。
1. はじめに: 「賢く話し合えば賢く解ける」のか?
「複数の LLM エージェントを協調させることで、より複雑な問題が解決できるのではないか」
大規模言語モデル(LLM: Large Language Model)が単体で多くのタスクをこなせるようになった今、この疑問が関心の中心になりつつあります。
実際、AutoGen、MetaGPT、CAMEL、LangGraph、CrewAI といったフレームワークが次々と登場し、財務アナリスト・コードレビュアー・市場調査担当といった役割を持つ複数のエージェントを協働させる試みが盛んになっています。会話・役割の付与・パイプラインなど形は違えど、どれも 「単一の万能エージェント」ではなく「専門特化したエージェントを束ねる」 発想に立っています。
なぜこのような方向に舵を切っているのか。その背景には、しばしば暗黙のうちに前提とされる3つの素朴な期待があります。
- 賢いエージェントを並べれば、システムも賢くなる — 単体で優秀な LLM を集めれば集合知も高まるはず。
- 役割分担すれば、徹底性が上がる — 分業すれば見落としが減り、網羅的な答えに近づくはず。
- エージェント同士が話し合えば、品質も上がる — 会話やレビューを通じて誤りを補正できるはず。
しかし、現実はそう単純ではありません。エージェントを増やすほど計算コストは膨らむのに、肝心の出力は「広く浅く」になったり、重要な観点を見落としたまま「もっともらしい結論」だけが返ってきたり、矛盾する事実を内部で抱えたまま統合されたりします。問題は「賢く話し合うこと」自体ではなく、エージェントたちが導き出した結果の集まりが、そもそも元の問い(ユーザのクエリ)にきちんと応えているか。その検証を誰も独立に行わない構造に本質的な問題があります。
本記事で紹介する VMAO(Verified Multi-Agent Orchestration)フレームワークは、この欠落に対して 「オーケストレーション層に検証器を置き、不足があれば計画を組み直す」 という発想で応えたものです。VMAO の核心は、個々のエージェントを賢くすることでも会話パターンを洗練することでもなく、 結果の集まりに対する「品質検査」をシステムの中心に据えること にあります。
この問題意識を踏まえて、まずは既存のマルチエージェント研究が何を中心に設計されてきたのかを整理します。
2. これまでの研究は何を中心に据えてきたか
VMAO の特徴を理解するために、まずこれまでのマルチエージェントが何を中心に据えて設計されてきたかを押さえておく必要があります。代表的なマルチエージェント型のフレームワークは、採用する協調戦略の点で見ると次のようにかなりの多様性を見せています。
| フレームワーク名 | 協調戦略 | 概要 |
| AutoGen | 会話で進める | 複数のエージェントに相談させながら答えを作る |
| CAMEL | 役割を演じさせる | 「ユーザ役」「アシスタント役」のように役割を決めてやり取りさせる |
| MetaGPT | 開発工程に沿って進める | 要件定義、設計、実装、テストのように担当と順番を決める |
| HuggingGPT | 司令塔が振り分ける | 中央のモデルが、得意分野ごとの専門モデルに仕事を配る |
上の表は「協調戦略そのものを提案した研究」を並べたものです。一方、実務でよく使われる LangGraph(状態付きグラフの実行ランタイム)や CrewAI(「役割+タスク」の高レベル抽象)は、特定の協調戦略を主張するというより、こうした戦略を実装するための基盤・SDKに位置づけられます。AutoGen 的な会話パターンや MetaGPT 的なパイプラインだけでなく、後述する VMAO のような DAG 分解+検証ループも、こうした基盤の上に構築しうる戦略の一例として捉えられます。
表 1 のフレームワークはいずれも、次の3点をインターフェースの中心に据えています。
- エージェントがどう話し合うか
- どう役割を分担するか
- どう情報を渡し合うか
一方で、どのフレームワークも 「元のクエリに本当に応えられているか?」 という観点を中心には据えていません。
VMAO は、この空白を埋めるために設計されたフレームワークです。協調の中心を「会話」から「結果の検証」へ移したのが、VMAO の出発点になります。
単一 LLM の出力品質を高める研究(Self-Refine、Reflexion、Chain-of-Thought、Tree-of-Thoughts など)も存在しますが、いずれも単一の回答あるいは単一 LLM の内部で動く仕組みで、複数エージェントの結果集合をまとめて評価するものではありません。
3. VMAO の協調戦略:検証を中心に据える
VMAO が中心に置くのは、協調の仕方そのものではなく、複数のエージェントが出した結果を集めたあとで、その結果全体が元のクエリにきちんと応えているかを検査することです。足りない観点があれば、その場で計画を組み直し、もう一度必要なエージェントに作業させます。この発想の詳細を順に見ていきましょう。
3.1 検証中心の設計における 3 つの原則
まず、協調の中心を「検証」に置くとはどういうことか。VMAO では、この考え方を次の 3 つの原則として捉えています。
1. オーケストレーション層で検証する:検証は各エージェントの内部ではなく、それらを束ねる オーケストレーション層 で行う。「個々のエージェントが役を演じきれたか」ではなく、「全結果を合わせて元のクエリに応えられているか」を問う。
2. 独立した検証器を使う:検証は実行担当のエージェントとは 別のモデル(VMAO では、より能力の高い Claude Opus 4.5)が担う。実行と評価を分離することで、自己評価バイアス(自分の出力を甘く採点する傾向)を抑える。
3. 検証は再計画を駆動する:検証は結果を判定して終わるのではなく、次の行動を起動する。スコアの低いサブ質問は再試行され、足りない観点には新しいサブ質問が追加されるなど、検証結果をもとに計画そのものが組み直される。
これら 3 つの原則は、後ほど見る Plan–Execute–Verify–Replan の 5 フェーズループとして具体化されています。次節ではその前提として、VMAO のあらゆる実行を支える DAG(有向非巡回グラフ)を整理しておきます。
3.2 準備:有向非巡回グラフ(DAG)
VMAO の設計を理解するうえで、有向非巡回グラフ(Directed Acyclic Graph、以下 DAG)を理解していることが望ましいです。以降で登場する QueryPlanner の出力や DAGExecutor の動作は、すべてこの構造に支えられています。
グラフと DAG
まずグラフ(Graph)とは、対象同士の関係を表すために、ノード(Node)の集まりと、それらをつなぐエッジ(Edge)の集まりで構成されるデータ構造のことです。形式的には、ノード集合 $V$ とエッジ集合 $E$ の組 $G = (V, E)$ として書きます。
DAG は、グラフのうち次の2条件を満たすものを指します。
1. 有向(directed):各エッジに向きがある。すなわち $E \subseteq V \times V$ であり、エッジ $e = (u, v) \in E$ は「$u$ から $v$ へ向かう」と読みます。
2. 非巡回(acyclic):どのノード $v \in V$ から出発しても、エッジをたどって $v$ 自身へ戻る経路が存在しない。
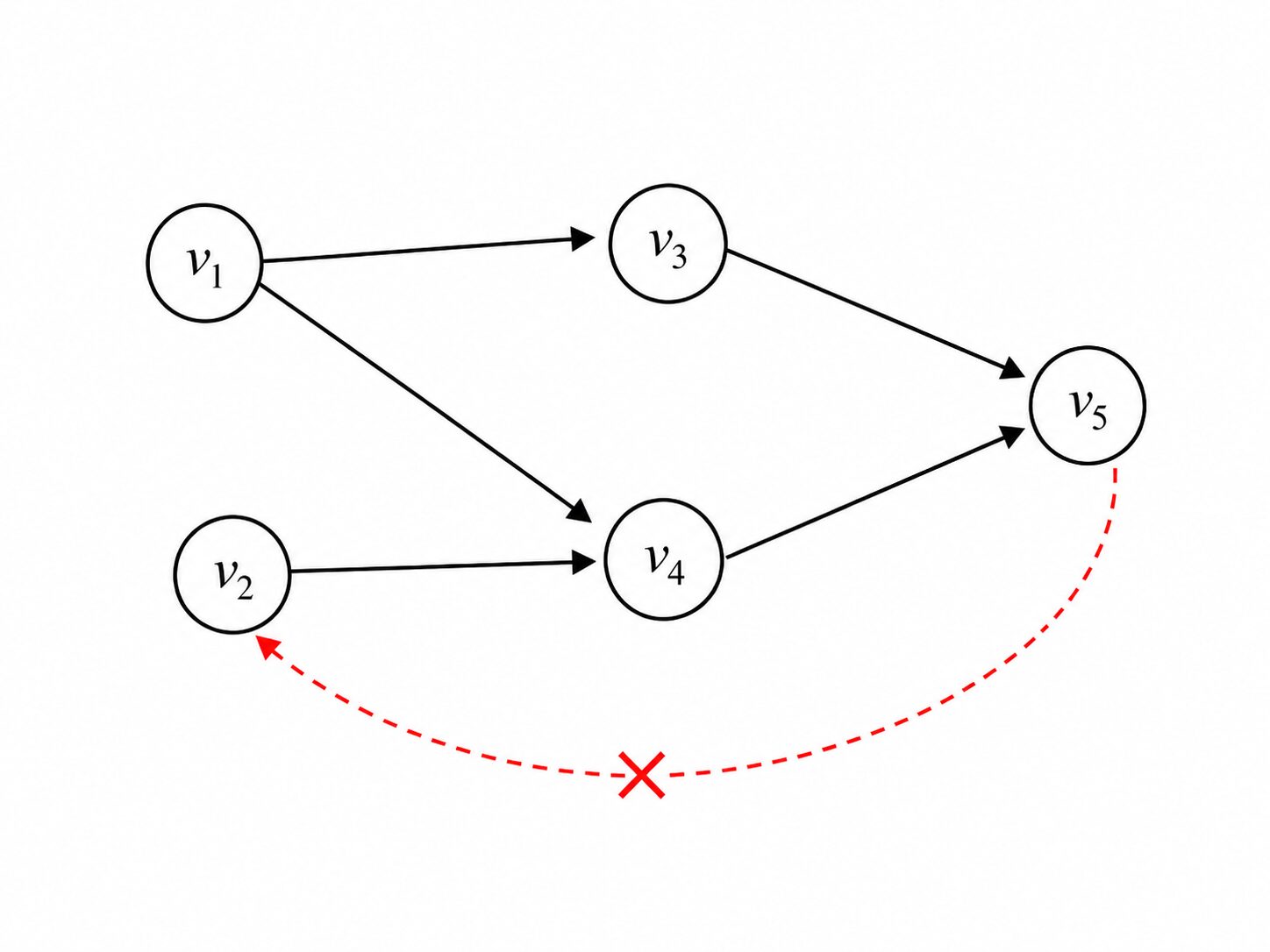
図1:有向非巡回グラフ(DAG)の例
5つのノード $v_1, \ldots, v_5$ と、それらを結ぶ有向エッジ $v_1 \to v_3$、$v_1 \to v_4$、$v_2 \to v_4$、$v_3 \to v_5$、$v_4 \to v_5$ から成るグラフです。これらのエッジをどう辿っても、たどった先からスタート地点に戻ることはできません。赤い破線(×印)で示したエッジ $v_5 \to v_2$ を加えると、$v_2 \to v_4 \to v_5 \to v_2$ という閉路ができてしまうため、DAG ではなくなります。
![]() トポロジカル順序
トポロジカル順序
DAG では、矢印の先にあるノードを、矢印の元より先に実行しないように並べられます。たとえば $u \to v$ なら、必ず $u$ を先に置き、その後に $v$ を置きます。このような並べ方をトポロジカル順序と呼びます。上の図では $v_1, v_2, v_3, v_4, v_5$ や $v_2, v_1, v_4, v_3, v_5$ がその例です。VMAO は、サブ質問をこの順序に沿って実行します。
VMAO で DAG はどう使われるか
VMAO ではこの構造を、次のように対応づけて使っています。
- ノード = サブ質問(クエリを分解した単位)
- エッジ = サブ質問の依存関係($A$ の答えが $B$ に必要なら $A \to B$)
具体例
対象クエリ: 「ある会社の業績について、前年比で何が変わったか」
このクエリは、次の 3 つのサブ質問に分解できます。
- $A$:今年の業績データを取得する
- $B$:去年の業績データを取得する
- $C$:$A$ と $B$ を比較して、変化点をまとめる
ここで $C$ は $A$ と $B$ の結果を必要とするため、$A \to C$、$B \to C$ というエッジが引かれます。こうしてできあがるのが、VMAO で扱う DAG です。
なぜ VMAO は DAG を採用するのか
DAG を使う最大のメリットは、「依存関係」と「並列性」という一見相反する性質を、ひとつの構造で自然に同時表現できる ことにあります。
- 依存関係が直感的:$A$ が $B$ の前提なら $A \to B$ と書くだけで順序制約が表現でき、循環も起きません。
- 高い並列性:互いに依存しないサブ質問(上の例なら $A$ と $B$)は同時に実行できます。
- 計画が読める:DAG は人間にとっても読みやすく、プランナーがどんな分解を作ったかを後から目視確認・デバッグできます。
この性質を使うと、「依存関係を尊重した正しい順序で、かつ可能な限り並列に」サブ質問を実行する戦略が、自然に書き下せます。
3.3 Plan–Execute–Verify–Replan の 5 フェーズループ
VMAO は Plan → Execute → Verify → Replan → Synthesize という 5 つのフェーズで実行・検証していきます(図2)。
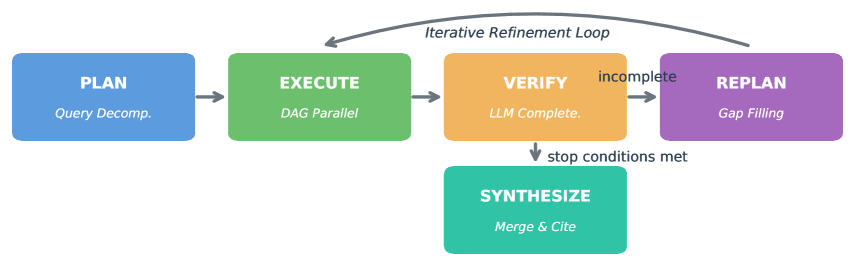
図2:Plan-Execute-Verify-Replan の 5 フェーズアーキテクチャ
クエリを受け取った VMAO は、Plan でサブ質問の DAG に分解し、Execute で並列実行する。Verify が結果全体を評価し、不足が見つかると Replan で計画を組み直して、再び Execute へ戻る。停止条件を満たした時点で Synthesize に進み、最終的な回答へまとめる。
各フェーズの役割を整理すると、表2のようになります。
| フェーズ | 役割 |
| Plan | クエリをサブ質問の DAG に分解し、担当エージェントを割り当てる |
| Execute | 依存関係を尊重しながら、サブ質問を並列に実行する |
| Verify | 集合的な結果が元のクエリに応えているかを、独立した検証器が判定する |
| Replan | 不足が見つかった場合に計画を組み直す(再試行・新規サブ質問の追加など) |
| Synthesize | 停止条件を満たした時点で、最終的な回答へまとめあげる |
ここで重要なのは、Verify と Replan が反復ループとして組み込まれている点です。従来のマルチエージェントは、多くの場合、「分解 → 実行 → 出力」という一方通行の流れでした。VMAO では、実行結果を毎回検証し、必要であれば計画を組み直して再実行します。このことが「検証を中心に据える」ことの意味です。
3.4 3 層エージェント分類
VMAO では、実行を担当する専門エージェントも整理されています。単に多数のエージェントを並べるのではなく、それぞれを 3 つの機能層(Tier) に分けて扱います(図3)。

図3:機能別 3 層エージェント分類
第 1 層(データ収集) → 第 2 層(分析) → 第 3 層(出力)の順に情報が流れる構造です。市場調査や財務分析など、現実のリサーチ業務でよく見られる処理の流れを反映しています。
| 層 | 役割 | 含まれるエージェント例 |
| 第 1 層:データ収集 | 多様なソースから情報を集める | ベクトル検索(RAG)、Web 検索、財務データ取得、競合情報収集 |
| 第 2 層:分析 | 収集データに対して推論や分析を行う | 分析、推論、生データ処理 |
| 第 3 層:出力 | 最終的な成果物を生成する | 文書生成、可視化 |
この分類の利点は、サブ質問ごとに必要な能力を選びやすくなることです。たとえば、まだ材料が足りない段階では第 1 層のエージェントが必要になります。すでに情報が集まっていて、そこから傾向や意味を読み取る段階では第 2 層が中心になります。最終的なレポートや図表に落とし込む段階では第 3 層が使われます。
この階層を明示することで、計画を立てるエージェント(QueryPlanner、4.1 節で詳述)は、サブ質問ごとに「どの層のどのエージェント種別が適しているか」を判断しやすくなります。
以上のように、VMAO は「会話の設計」だけでマルチエージェントを改善しようとするのではなく、結果を検証し、不足があれば計画へ戻す仕組みを中心に置いています。
この仕組みが具体的にどのようなアーキテクチャとして実装されているのかを次に見ていきます。
4. アーキテクチャの詳細
4.1 Plan:DAG 分解(QueryPlanner)
Plan フェーズを担当するのが QueryPlanner です。与えられたクエリを、実行可能なサブ質問の DAG へと分解する役割を持ち、VMAO のすべての処理の起点となります。
QueryPlanner の役割
QueryPlanner は LLM を用いて、次の 4 つを 同時に 決定します。
- クエリをどのサブ質問群に分解するか
- 各サブ質問をどのエージェント種別に割り当てるか(3.4 節の 3 層分類から選ぶ)
- どのサブ質問が他のサブ質問の出力に依存するか
- 各サブ質問の実行優先度
これらをひとつの構造化された出力としてまとめることで、後段の DAGExecutor、ResultVerifier、AdaptiveReplanner はこのデータをそのまま読み取って動作します。
サブ質問の構造
QueryPlanner が出力する各サブ質問には、次の情報が含まれます。
| フィールド | 説明 |
id |
一意の識別子(例:sq_001) |
question |
具体的かつ回答可能なサブ質問の文 |
agent_type |
担当エージェントの種別(3.4 節の 3 層分類から選択) |
dependencies |
先に完了している必要があるサブ質問の id 一覧 |
priority |
実行優先度(1〜10、値が大きいほど高い) |
context_from_deps |
依存元の結果を文脈として与えるかどうか(真偽値) |
verification_criteria |
その回答が十分で適切かを評価するための基準(Verify フェーズで使用) |
ここで重要なのは、Plan フェーズの段階で verification_criteria まで決まっている という点です。つまり「このサブ質問が満足のいく形で答えられたかどうか」をどう判定するかも、計画と同時に作られています。後段の Verify フェーズは、この基準に照らして評価を行うことになります。
具体例
対象クエリ: 「ある会社の業績について、前年比で何が変わったか」
3.2 節ではこのクエリを、3 つのサブ質問 $A, B, C$(と $A \to C$、$B \to C$ のエッジ)に分解する様子を見ました。QueryPlanner はこの計画を、次の 3 件のレコードとして出力します。
1. sq_001:今年の業績データを取得する
agent_type:財務エージェント(第 1 層)dependencies:なし(sq_002 と並列に実行できる)context_from_deps:falseverification_criteria:主要な財務指標が揃っており、年度が一致しているか
2. sq_002:去年の業績データを sq_001 と同じ指標で取得する
agent_type:財務エージェント(第 1 層)dependencies:なし(sq_001 と並列に実行できる)context_from_deps:falseverification_criteria:sq_001 と同じ年度・指標で取得されているか
3. sq_003:今年と去年の業績を比較し、変化点と要因をまとめる
agent_type:分析エージェント(第 2 層)dependencies:sq_001,sq_002(両方の結果が揃ってから実行される)context_from_deps:true(前 2 つの回答が文脈として前置される)verification_criteria:主要な変化点(増減幅・要因)が根拠とともに示されているか
4.2 Execute:DAG ベース並列実行
計画フェーズで得られた DAG を実際に走らせるのが DAGExecutor です。基本のアイデアは、「依存先がすべて完了しているサブ質問」を同じ世代として一斉に実行し、それを終端まで繰り返すというものです。
並列実行のステップ
DAG をトポロジカル順序に従って実行するとき、各時点で「依存先がすべて完了していて、いますぐ実行できるサブ質問の集合」が決まります。VMAO では、毎ステップこの集合の中から、並列度の上限 $k$(既定 $k = 3$)を超えないように優先度の高い順に top-$k$ 件を選んでバッチ化し、並列に走らせます。
- 最初のステップ:依存先を持たないサブ質問が候補になります。
- 次のステップ以降:直前までの結果が揃ったことで実行可能になったサブ質問が、新たに候補に加わります。
- これを DAG の終端まで繰り返します。バッチで選ばれなかったサブ質問は、次のステップで再度候補に上がります。
文脈伝播:context_from_deps
単に並列に流すだけでは、依存元の答えを下流のサブ質問に渡せません。VMAO では、サブ質問ごとに context_from_deps というフラグを持ち、これが有効なら、依存元の回答群をプロンプトの先頭に文脈として前置してから実行します。これにより、上流の発見を下流の問いに自動でつなげられます。
DAG ベースの並列実行
以上の流れを擬似コードに落としたものが、下の Algorithm 1 です。
入力:
- 実行計画 $P = (Q, G)$1:サブ質問の集合 $Q$ と、それらの依存関係 $G$ の組
- 最大並列数 $k$:同時に走らせるサブ質問数の上限
出力:
- 結果集合 $R = \{r_1, \ldots, r_n\}$2:各サブ質問に対する回答の集合
$$
\begin{array}{rl}
& \textcolor{gray}{\triangleright\ \text{完了済みサブ質問の集合を空集合で初期化する}} \\
1\colon & \text{completed} \gets \emptyset \\
& \textcolor{gray}{\triangleright\ \text{すべてのサブ質問が完了するまで、以下のループを繰り返す}} \\
2\colon & \textbf{while } |\text{completed}| < |Q| \textbf{ do} \\
& \quad \textcolor{gray}{\triangleright\ \text{今回実行できる「ready なサブ質問」を集める:}} \\
& \quad \textcolor{gray}{\phantom{\triangleright\ }\text{依存先 deps(q)(先に完了しておくべき他のサブ質問たち)が}} \\
& \quad \textcolor{gray}{\phantom{\triangleright\ }\text{すべて完了済みで、かつ q 自身がまだ実行されていないものを選ぶ}} \\
3\colon & \quad \text{ready} \gets \{\, q \in Q \;:\; (\text{deps}(q) \subseteq \text{completed}) \,\wedge\, (q \notin \text{completed}) \,\} \\
& \quad \textcolor{gray}{\triangleright\ \text{ready の中から優先度の高い順に k 件を選び、}} \\
& \quad \textcolor{gray}{\phantom{\triangleright\ }\text{今回並列に実行するバッチとする}} \\
4\colon & \quad \text{batch} \gets \text{top-}k(\text{ready},\ \text{by} = \text{priority}) \\
& \quad \textcolor{gray}{\triangleright\ \text{選んだ k 件のサブ質問を並列に実行する}} \\
5\colon & \quad \text{results} \gets \text{parallel\_execute}(\text{batch}) \\
& \quad \textcolor{gray}{\triangleright\ \text{実行結果を、サブ質問 q とその回答 r のペアとして順に処理}} \\
6\colon & \quad \textbf{for } (q, r) \text{ in results } \textbf{do} \\
& \quad\quad \textcolor{gray}{\triangleright\ \text{このサブ質問が「依存元の結果を文脈に取り込む」}} \\
& \quad\quad \textcolor{gray}{\phantom{\triangleright\ }\text{設定になっている場合:}} \\
7\colon & \quad\quad \textbf{if } q.\text{context\_from\_deps} \textbf{ then} \\
& \quad\quad\quad \textcolor{gray}{\triangleright\ \text{依存元のサブ質問の回答を文脈として前置し、}} \\
& \quad\quad\quad \textcolor{gray}{\phantom{\triangleright\ }\text{現在の回答 r を補強する}} \\
8\colon & \quad\quad\quad r \gets \text{enrich\_with\_context}(r,\ \{R[d] : d \in \text{deps}(q)\}) \\
9\colon & \quad\quad \textbf{end if} \\
& \quad\quad \textcolor{gray}{\triangleright\ \text{回答 r を結果マップ R に保存し、q を完了集合に加える}} \\
10\colon & \quad\quad R[q.\text{id}] \gets r;\ \text{completed} \gets \text{completed} \cup \{q\} \\
11\colon & \quad \textbf{end for} \\
12\colon & \textbf{end while} \\
& \textcolor{gray}{\triangleright\ \text{すべてのサブ質問の結果集合 R を返す}} \\
13\colon & \textbf{return } R
\end{array}
$$
1 $Q$ はサブ質問の集合、$G \subseteq Q \times Q$ は依存関係を表し、$(q’, q) \in G$ は「$q’$ が $q$ より先に完了している必要がある」ことを意味します。3 行目に現れる $\mathrm{deps}(q) = \{q’ : (q’, q) \in G\}$ は、$q$ が依存しているサブ質問の集合を返す関数です。
2 $R$ は、各サブ質問の $\mathrm{id}$ をキー、その回答を値とするキー・バリューマップとして扱います。$R[d]$ は依存先 $d \in \mathrm{deps}(q)$ の保存済み回答を指し、8 行目に現れる $\{R[d] : d \in \mathrm{deps}(q)\}$ は $q$ が依存しているサブ質問すべての回答集合となります。実装上は、この回答集合を文脈として実行前のプロンプトに前置します。ループ終了後、$R$ の値の全体が、出力で結果集合 $\{r_1, \ldots, r_n\}$ となります。
4.3 Verify:ResultVerifier
Verify フェーズを担当するのが ResultVerifier です。DAGExecutor が実行した各サブ質問の結果を、4.1 節で計画段階に決められた verification_criteria に照らして評価し、次の 6 項目を返します。
status:complete/partial/incompletecoverage_score:必要な観点をどれだけ拾えているかを示す 0〜1 の数値(網羅性)confidence_score:得られた結果がどれだけ確からしいか(出典の確かさや内部矛盾のなさ)を示す 0〜1 の数値。網羅性とは独立に評価され、4.4 節の「高信頼度」停止条件で利用されるmissing_aspects:欠落している論点contradictions:結果同士で食い違っている記述recommendation:accept/retry/escalate
検証を担当するのは、実行を担うエージェントとは異なるモデル(VMAO の実装では Claude Opus 4.5)です。3.1 節で挙げた 独立検証器 の原則を実装した部分にあたります。
4.4 停止条件:品質とコストの明示的トレードオフ
反復ループを「いつ打ち切るか」は、品質とコストのトレードオフを決める重要な判断です。VMAO はこれを 5 つの停止条件 として明示的に定義しています。
| 条件 | しきい値 | 根拠 |
| 統合可能(Ready for Synthesis) | 網羅性 80% | サブ質問への回答が十分に揃っている |
| 高信頼度(High Confidence) | 信頼度 75%、網羅性 50% | カバレッジが部分的でも信頼性が高い |
| 収穫逓減(Diminishing Returns) | 改善幅 5% 未満 | これ以上反復しても得られる利得が小さい |
| トークン予算(Token Budget) | 100 万トークン | コストの絶対上限 |
| 最大反復回数(Max Iterations) | 3 回 | 反復回数の絶対上限 |
各条件は毎回の Verify フェーズの後に評価され、いずれかひとつでも満たされた時点で Synthesize へ進みます。これらは設定可能なため、「速度優先で最大 2 反復」「徹底重視で最後まで答えを揃える」といったポリシーを運用側で選べます。
4.5 Replan:AdaptiveReplanner
Verify で不足や矛盾が見つかったときに、次にとるべきアクションを決めるのが AdaptiveReplanner です。ResultVerifier が出した recommendation と missing_aspects に応じて、次のいずれかを選びます。
- 再試行(retry):網羅性スコアが低かったサブ質問を、同じ問いで再実行する
- 新規サブ質問の追加:欠けていた観点を埋めるため、DAG に新しいノードを追加する
- 複数試行のマージ:再試行で得た複数の回答を統合して、より網羅的な単一の回答にする
重要なのは、過去の結果を捨てないことです。再試行で得た回答で「上書き」するのではなく、両方を保持して後で統合します。これにより反復ごとに少しずつ網羅性が積み上がる 段階的精緻化(progressive refinement) が実現します。Self-Refine のような単一応答レベルの反復改善とは違い、VMAO は 集合的結果としての網羅性 を押し上げていく仕組みです。
4.6 Synthesize:階層的合成
最後の Synthesize フェーズでは、蓄積されたサブ質問の結果を 最終的な回答 へまとめあげます。ここで実用上問題になるのが、結果が多すぎて LLM のコンテキスト長に収まらないケースです。論文では、結果集合が 15,000 文字を超える、あるいは 10 件以上に達した時点で、直接統合がコンテキスト超過のリスクを抱えると述べられています。
VMAO はこれを 階層的合成(hierarchical synthesis) で解決します。
1. 結果を agent_type(3.4 節の 3 層分類)ごとにグループ化する
2. 各グループ内で要約する(圧縮)
3. グループ要約を、出典の帰属を保ちながら最終回答へ統合する
この 2 段階構造により、結果集合がコンテキスト長を超える場合でも、情報損失を抑えながら最終回答へ集約 しやすくなります。出典の帰属が保持されるため、もう一つの評価軸である ソース品質 にも寄与します。
![]() 実装にあたっての技術スタック
実装にあたっての技術スタック
VMAO は LangGraph(フェーズ管理)+ Strands Agent(エージェント内ループ)+ MCP(外部ツール接続)の構成で、AWS Bedrock 上で動作します。実行には Claude Sonnet 4.5、検証には Claude Opus 4.5 をそれぞれ割り当て、検証と実行で異なるモデルを使うことで「独立検証器」の原則を実現しています。
5. 実験と評価
ここまで見てきた VMAO の設計は、実際にどれだけの効果を生むのか。論文では、市場調査タスクを対象に既存手法との比較を行っています。
5.1 実験設定
評価対象は、各分野の専門家が集めた 25 件の市場調査クエリ で、次の 4 カテゴリに渡ります。
| カテゴリ | 件数 | 概要 |
| パフォーマンス分析 | 8 | 業績や指標がどう変化し、なぜ変わったのかを問う |
| 競合インテリジェンス | 7 | 市場での自社の立ち位置や、競合との違いを問う |
| 財務調査 | 5 | 財務数値を事業の動きとあわせて読み解く |
| 戦略評価 | 5 | 複数の観点を統合して戦略の妥当性を判断する |
評価では、正確性ではなく網羅性 を測ります。「顧客満足度の低下を説明する要因は?」のような問いには単一の正解が存在しないためです。代わりに、「関連するすべての観点が裏付けとともに扱われているか」(網羅性)と「回答が検証可能なソースに基づいているか」(ソース品質)を 1〜5 のスケールで採点します。
採点は 2 段階で行われます。まず、LLM ジャッジ(LLM-as-a-Judge、Claude Opus 4.5)が「網羅性」「ソース品質」など、採点項目と尺度をあらかじめ定めた採点基準に沿って各回答を採点します。その後、人間の専門家が内容を確認し、必要に応じてスコアを調整します。論文によると、人間の調整が入ったのは全体の 15% 未満で、調整幅も多くは ±0.5 程度と小さく、LLM と人間の評価がほぼ一致していたことが示されています。
比較対象は次の 3 構成です。いずれもエージェント実行には Claude Sonnet 4.5 を使い、使えるツールも統一しています(差は協調戦略のみ)。
- 単一エージェント:すべてのツールを持つ 1 つの推論エージェント
- 静的パイプライン:あらかじめ決められた順序(RAG → Web → 財務 → 分析 → 統合)、検証や再計画は持たない
- VMAO:DAG 分解・並列実行・検証駆動の再計画・停止条件をすべて備えた本フレームワーク
5.2 主な結果
網羅性とソース品質を比較した結果は表7のとおりです。
| 指標 | 単一エージェント | 静的パイプライン | VMAO |
| 網羅性 | 3.1 | 3.5 | 4.2(+35%) |
| ソース品質 | 2.6 | 3.2 | 4.1(+58%) |
1〜5 のスケール、値が大きいほど良い。±% は単一エージェントを基準とした相対改善率。
VMAO はいずれの指標でも他の構成より優れた結果を示しています。特にソース品質が +58% 向上したのは、情報を幅広く集めて、出典を明示した上で統合する という設計(4.6 節・階層的合成)が効果的だったと言えるでしょう。静的パイプラインも単一エージェントより改善していますが、初期のエージェントが十分でない回答を返した場合に柔軟に対応できないため、VMAO ほどの効果は得られていません。
5.3 リソース消費
品質向上の代償として、VMAOの計算リソースは大きく増えることがわかっています。
| 指標 | 単一エージェント | 静的パイプライン | VMAO |
| トークン消費 | 100K | 350K | 850K(×8.5) |
| 実行時間 | 165 秒 | 420 秒 | 900 秒(×5.5) |
1 クエリあたりの平均。赤セルの ×N は単一エージェントを基準とした倍率。
また、論文の評価では、クエリの 75% 以上が品質基準ではなくリソース制約(収穫逓減・最大反復回数・トークン予算)で打ち切られていました。これは VMAO が 4.4 節で挙げた品質側のしきい値(網羅性 80%・信頼度 75%)に届く前に、反復を重ねるうちにリソース上限へ達してしまうケースが多いということです。論文の設定は このしきい値を高めに置いて徹底性を優先しているため、速度を取りたければ下げる、さらに突き詰めたければ上げる、という調整余地があります(4.4 節の停止条件はそのためのインタフェースです)。
なお、ここから先は論文では明示的に検討されていない筆者の補足ですが、実務でコストを抑えたい場合は、たとえば 網羅性しきい値を 60% 程度に下げる、最大反復回数を 2 回に絞る、といった運用が考えられます。逆に、調査の精度を最優先するならば、しきい値はそのままに トークン予算を引き上げて反復を最後まで回し切るのも一案です。いずれにしても、品質側とコスト側のしきい値はクエリの種類や用途ごとに調整すべきパラメータと捉えるのが実用的です。
5.4 カテゴリ別の効き方
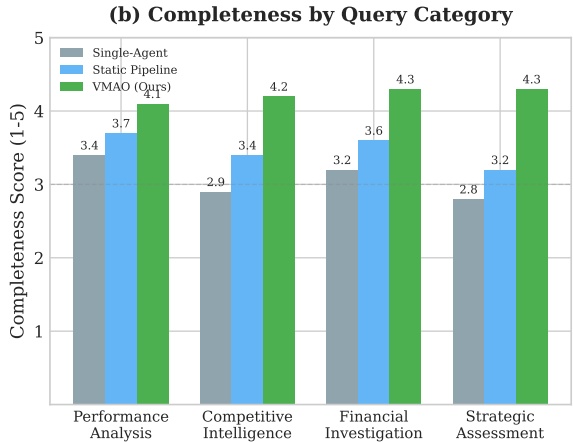
図4:クエリカテゴリ別の網羅性スコア(1〜5 のスケール)
VMAO(緑)はすべてのカテゴリで他構成を上回ります。戦略評価(Strategic Assessment) で最大の改善幅を示し、パフォーマンス分析(Performance Analysis) ではやや控えめにとどまります。
改善幅はクエリのカテゴリによって異なります。戦略評価で網羅性が 2.8 → 4.3 と最大の改善を見せた一方、パフォーマンス分析は 3.4 → 4.1 と控えめでした。
この違いは、VMAOの設計思想と一致しています。戦略評価のようにさまざまな観点を横断して統合するタスクでは、検証ループによって「見落としていた観点」を多く拾い上げることができるため、再計画の効果が大きく表れます。
一方でパフォーマンス分析は、データソースが明確に定義されている場合が多く、単一エージェントでも十分に対応しやすいため、VMAOによる追加コストに見合うほどのリターンが少なくなりがちです。
言い換えれば、VMAO は 問いが開いていて、かつ複数の観点を統合する必要がある ときほど真価を発揮するフレームワークだと言えます。
VMAO にはいくつか注意すべき点もあります。
- コスト:トークン消費 ×8.5 倍で、低レイテンシ用途には合わない
- 評価規模:クエリ 25 件と少なく、スコアのばらつきも示されていないため、今回の改善幅が他のクエリでも再現するかは判断しづらい
- アブレーション:DAG 並列化・3 層分類・停止条件・検証器のどれがどれだけ寄与したかは未解明
- LLM ジャッジバイアス:検証器が LLM である以上、バイアスは残る
いずれも VMAO の主張を覆すものではありませんが、「重心を検証に置く」設計を本格的に普及させるには引き続き研究が必要です。
6. おわりに
マルチエージェントシステムの設計がこれまで「会話」を中心に組み立てられてきた経緯を振り返り、そこに 「検証」 を中心に据え直したフレームワーク VMAO を紹介しました。
実務においても本研究の内容の一部を取り入れることは可能だと思います。自前のマルチエージェントシステムの改善に活かしてみてはいかがでしょうか。
参照 URL
- VMAO 論文: https://arxiv.org/abs/2603.11445
- AutoGen: https://arxiv.org/abs/2308.08155
- CAMEL: https://arxiv.org/abs/2303.17760
- MetaGPT: https://arxiv.org/abs/2308.00352
- HuggingGPT: https://arxiv.org/abs/2303.17580
- Self-Refine: https://arxiv.org/abs/2303.17651
- Reflexion: https://arxiv.org/abs/2303.11366
- Chain-of-Thought: https://arxiv.org/abs/2201.11903
- Tree-of-Thoughts: https://arxiv.org/abs/2305.10601
- LangGraph: https://github.com/langchain-ai/langgraph
- CrewAI: https://github.com/crewAIInc/crewAI
- Strands Agent: https://github.com/strands-agents/sdk-python
- MCP: https://modelcontextprotocol.io/