AI コーディングによる開発が日常的になった今、リポジトリに AGENTS.md や CLAUDE.md といったコンテキストファイルを置く慣行が広まっています。実際に、主要な AI 企業である OpenAI や Anthropic がこの慣行を推奨しており、Google も現行の Gemini CLI 公式ドキュメントで同様の仕組みを案内しています。多くのオープンソースリポジトリがこれらのファイルを含んでいます。
しかし、このファイルは 本当に効果的なのでしょうか?
この問いに向き合い検証した論文を紹介します。
紹介する論文
| 項目 | 内容 |
| 論文名 | Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? |
| 公開年 | 2026年 |
| URL | https://arxiv.org/abs/2602.11988 |
本記事の要約
AGENTS.md のようなコンテキストファイルは、期待されるほど大きな効果を示さず、むしろエージェントの回り道を増やしてコストを押し上げる傾向がある。開発者が必要最小限にまとめたファイルは LLM 自動生成より良い傾向があるものの、改善幅は小さいとされている。
ポイント
-
背景と検証:
現在広く使われているAGENTS.mdなどのコンテキストファイルに、実際の効果があるのかを検証した論文です。 -
研究結果:
LLM が自動生成したファイルは平均的に成功率を下げ、コストを 20% 以上増加させる傾向が見られます。開発者提供のコンテキストファイルは LLM 生成より良いものの、改善幅は限定的です。 -
現場での実践的アドバイス:
実務では、自動生成に任せるよりも、開発者が本当に必要なツール設定や注意事項だけを絞って記述したファイルのほうが有効だと考えられます。
はじめに
大規模言語モデル(LLM)のソフトウェア開発への統合により、複雑なプログラミングタスクに取り組める自律型コーディングエージェントが登場しました。
例えば、Cursor や Cline、Claude Code などは、LLM を活用して探索、編集、テスト実行といった作業を支援する代表的なツールです。
こうしたエージェントの利用が広がるにつれて、コードベースの理解を助けるために AGENTS.md や CLAUDE.md のようなリポジトリレベルのコンテキストファイルを置くことが、業界の慣行として広まりました。
AI 企業である OpenAI や Anthropic もこの慣行を後押ししており、多くのオープンソースリポジトリがそのようなファイルを含んでいます。例えば、Codex は AGENTS.md を自動で読み込み、/init で AGENTS.md のひな型を作ると明記されています。Claude Code にも同様の /init コマンドがあります。
また、現行の Gemini CLI 公式ドキュメントでも GEMINI.md と /init が案内されています。
では、このファイルを置くことは本当に有効なのでしょうか。広く採用されている一方で、こうしたコンテキストファイルの効果を大規模に検証した研究はまだ十分にされていません。
本論文では、著者らが「リポジトリレベルのコンテキストファイル(AGENTS.md、CLAUDE.md など)」がコーディングエージェントの性能を本当に向上させるのかを、体系的に検証しています。
問題提起と研究課題
通常、「コンテキストファイル」は自然言語の文字列で書かれたテキストファイルであり、内容は自由形式です。ただし、その役割を踏まえると、実際には次のような情報が書かれることが多いです(表1)。
| カテゴリ | 目的 | 具体例 |
| リポジトリ概要 | どこに何があるかの把握を助ける | ディレクトリ構成、主要モジュールの説明 |
| ツール/コマンド | 正しい実行手順で迷わないようにする | テスト実行、ビルド手順(例:pytest、npm run test) |
| コーディング規約 | 変更の一貫性を保つ | 命名規則、スタイルガイド、フォーマッタ |
| 依存関係/セットアップ | 再現可能な実行環境を作る | Python/Nodeのバージョン、依存導入手順 |
| プロジェクト固有の注意 | つまずきどころを減らす | 例外ルール、禁止事項、運用上の前提 |
近いの仕組みとして、
.cursor/rules/*.mdc があります。ただし Cursor Rules は frontmatter や globs で適用範囲を制御できるルール機構であり、リポジトリルートに置く単純なコンテキストファイルとは完全には同列ではありません。一方、GEMINI.md は AGENTS.md / CLAUDE.md とほぼ同列です。本研究で主に検証しているのは AGENTS.md と CLAUDE.md です。
コーディングエージェントが実世界のソフトウェアエンジニアリングタスクを完了するうえで、これらのファイルは本当に役立つのでしょうか。
エージェントのアライメントや能力を高めるとはなんとなく思われているものの、その主張を裏づける大規模な定量研究はほとんどありませんでした。
そこで、本論文の著者らは次のような具体的な問いを立てています。
- コンテキストファイルを用意すると、コーディングエージェントの行動はどのように変わるのか。
- LLM が生成したコンテキストファイルと、開発者が提供したコンテキストファイルの間にはどのような差があり、成功率にどう影響するのか。
- コンテキストファイルの利用は、運用コストにどのような影響を与えるのか。
- コンテキストファイルを読むことで、エージェントは探索や作業の筋道を立てやすくなるのか。
これらの問いに答えるために、論文ではコンテキスト認識型コーディングエージェントを評価するための実験フレームワークと、新しいベンチマークの両方を整備しています。
方法論と実験デザイン
この研究では、評価の偏りを抑えるために、「複数のエージェント構成の比較」と「エージェント行動の包括的な分析」という性質の異なる2つの評価設定を併用しています。
まず、論文全体の評価パイプラインを示したのが次の図です(図1)。
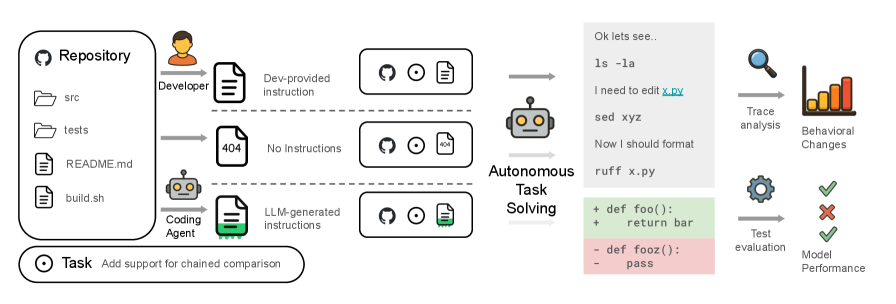
図1:本研究の全体フロー(原論文 Figure 1 を引用)
(左から順に)ソフトウェア開発プラットフォームである GitHub のリポジトリと過去のプルリクエストから評価タスクを構築し、Human・None・LLM の3条件でコーディングエージェントに解かせ、その結果を成功率と行動ログの両面から評価しています。
使ったベンチマーク
異なるシナリオをカバーするために、2つのデータセットを使用しています。
SWE-bench Lite
SWE-bench は、「Python リポジトリのある時点のスナップショットと Issue 本文」が与えられたときに、モデルまたはエージェントが コード編集によって不具合を直せるか を測るベンチマークです。
最終的な合否は、基本的に テストが通るかどうか で決まります。
特に SWE-bench Lite は、SWE-bench の中でも、評価を不必要に難しくしたり、外部参照が必要になったりするケースを除いた、比較的「閉じた」修正問題に絞ったベンチマークです。
なお、少なくとも論文の設定上、このベンチマークに含まれるリポジトリには開発者提供のコンテキストファイルは含まれていません。
AGENTbench
本論文で構築、提案されたベンチマークです。
そもそも SWE-bench Lite が対象にしているリポジトリには、少なくとも論文の設定上、開発者提供のコンテキストファイルが含まれていません。そのため、「実際に現場で使われているコンテキストファイル」の効果を直接測れません。
AGENTbench は、次のプロセスで作成されています。
AGENTbench の構築プロセス
ステップ1. リポジトリの選定 候補の収集
ルートにコンテキストファイル(AGENTS.md / CLAUDE.md)を持つリポジトリを GitHub で検索し、Python が主要言語でテスト一式があるものを候補にします。
ステップ2. PR(プルリクエスト) のフィルタリング 決定論的タスクの抽出
PR のうち、少なくとも Issue への参照があり、かつ Python ファイルを変更しているものを対象に、ルールと LLM の両方を用いて、「同じコード・同じ入力なら毎回同じ結果になる」といった決定論的な振る舞いに絞られている PR を選びます。
ステップ3. 実行環境の検証 テスト基盤の整備
コーディングエージェントを用いて、実行環境のセットアップ、テスト一式の実行、テスト結果の JSON 形式(machine-readable dictionary)でのリポジトリ直下への保存を行います。
ステップ4. タスク記述の標準化 Issue 文の生成
各 PR / Issue の記述が不十分な場合があるため、LLM エージェントに PR 説明や関連 Issue などを入力し、解法リークを避けながら、一定のテンプレートに沿った標準化済みのタスク記述(Issue 文)を生成します。
ステップ5. 評価用テストの作成 自動判定の整備
タスクの正誤を自動判定できるように、「修正前のコードでは失敗し、正解パッチ適用後のコードでは成功する」ようなユニットテストを LLM エージェントで生成します。その後、過度に実装依存なテストを人手で修正し、外部から観測可能な振る舞いを検証できる形に整備します(正しい動作でもテストが通らない場合があるため)。この手順で生成されたテストを実行すると、その PR で追加・変更されたコード行のうち平均約 75% が、実際にテストによって実行されます。
コンテキストファイル利用条件
2つのベンチマーク(SWE-bench Lite、AGENTbench)がそろったので、各タスクをエージェントに解かせていきます。
その際、本論文の目的である「コンテキストファイルを加えると性能がどの程度変化するか」を見るために、次の3条件で評価しています。
None(コンテキストファイルなし):
この条件が ベースライン です。コンテキストファイルを用いない、純粋なエージェントの解決能力を測れます。
AGENTbench の各タスクには、もともと開発者が用意したコンテキストファイル(AGENTS.md / CLAUDE.md)が存在しているため、評価時には 意図的に取り除いてから エージェントに渡します。
SWE-bench Lite でも同様に、コンテキストファイルが存在しない状態で評価します。
LLM(LLM が自動生成したコンテキストファイル):
各エージェントには、コンテキストファイルを自動生成するための専用コマンドが用意されています。
例えば、Codex や Claude Code は /init コマンドを使うことで、各リポジトリルートを起点に解析を行い、それぞれのプロジェクトの内容に沿ったコンテキストファイルを生成します(表2)。
本条件では、この LLM によって生成されたコンテキストファイルを与えてタスクを解かせます。
| エージェント | 生成用コマンド | デフォルトの生成ファイル | 論文で投入したファイル | 本論文で使用 |
| Claude Code | /init |
CLAUDE.md |
CLAUDE.md |
使用 |
| Codex | /init |
AGENTS.md |
AGENTS.md |
使用 |
| Qwen Code | /init |
QWEN.md |
AGENTS.md |
使用 |
| Gemini CLI | /init |
GEMINI.md |
– | 未使用 |
Qwen Code はデフォルトでは
QWEN.md、Gemini CLI はデフォルトでは GEMINI.md を生成しますが、いずれも設定(context.fileName)で別名や複数名への変更が可能です。本論文の実験では、Qwen Code には Codex と同様に AGENTS.md をコンテキストファイルとして投入しています。
論文によれば、GPT-OSS-120B による自動判定で、GPT-5.2 が生成したファイルの 99% がコードベースの概要(codebase overview)を含むとフラグされており、LLM が生成すると、ほぼ確実にリポジトリ全体の説明が入る傾向があるようです。
Human(開発者が提供したコンテキストファイル):
この条件は AGENTbench にのみ適用されます。
AGENTbench のリポジトリは、そもそも「コンテキストファイルを持つリポジトリ」から選ばれているため、実際にコミット済みの開発者提供ファイルが存在します。
この「開発者提供のコンテキストファイル」を、そのままタスクに与えます。
なお、論文では作成手段(手書きか自動生成か)までは区別していません。
Human は「developer-provided context file(開発者提供のファイル)」として定義されています。
これらの条件設計により、次の3軸の比較を同時に行えるようになっています。
LLMvs.None:LLM が自動生成したコンテキストファイルは本当に有効か。Humanvs.None:開発者提供のコンテキストファイルは有効か。Humanvs.LLM:開発者提供と自動生成のどちらが優れているか。
エージェントの設定および評価結果の信頼性確保について
タスクを解くのに使ったコーディングエージェントおよびモデルは次の通りです。Codex のみ2モデル構成のため、比較上は4種類の構成で評価しています。
| エージェント | 使用モデル |
| Claude Code | Sonnet-4.5 |
| Codex | GPT-5.2 / GPT-5.1 mini |
| Qwen Code | Qwen3-30B-Coder |
すべてのエージェントは、再現性を高めるために、LLM のランダム性をできるだけ抑える設定で評価されています。
温度(temperature)設定
Sonnet-4.5 と GPT-5.2 / GPT-5.1 mini は temperature 0 で評価されています。一方、Qwen3-30B-Coder は temperature 0.7、top-p 0.8 です。したがって、「すべてのエージェントで低温度にそろえて再現性を保証した」というよりは、単発評価を採用しつつ、各エージェントごとの設定で比較していると読むのが安全です。
単発(single-sample)の生成結果
もし同じタスクを 5 回実行して「一番よかった結果」を採用すると、モデル性能ではなく「試行回数の多さ」が効いてしまいます。そのため、同じタスクは 1 回だけ実行し、その結果で評価しています。
実験結果1:定量評価
本研究の結果は、「コンテキストファイルを用意すると良い」とする業界の一般的な推奨に疑問を投げかけるものであり、直感に反する興味深い内容になっています。
成功率への影響
まずタスク成功率を見ると、LLM によって生成されたコンテキストファイルは、多くの条件でむしろ逆効果 でした。具体的には、LLM 生成のコンテキストファイル(LLM)は、コンテキストファイルがない場合(None)と比べて、SWE-bench Lite では 0.5%、AGENTbench では 2%、タスク成功率が低下しています(図2)。
これに対して、開発者が提供したコンテキストファイル(Human)は、AGENTbench では LLM 生成より一貫して良く、コンテキストなしと比べても改善が見られます(Claude Code / Sonnet-4.5 構成を除く)。ただし改善幅は小さく、論文では平均 4% の向上にとどまっています。
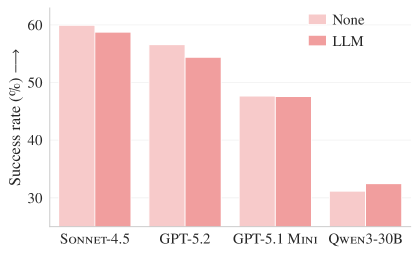
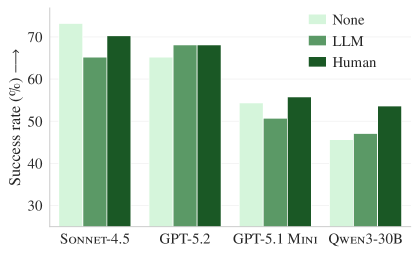
図2:タスク成功率の比較(SWE-bench Lite:左、AGENTbench:右)(原論文 Figure 3 を引用)
Claude Code(Sonnet-4.5)、Codex(GPT-5.2 / GPT-5.1 mini)、Qwen Code(Qwen3-30B-Coder)の4構成について、コンテキストあり(LLM または Human)と、なし(None)の条件下でタスク成功率を比較した結果です。
ステップ数と推論コストへの影響
この結果の内訳として、本論文では成功率とは別に、1タスクあたりのステップ数と推論コストも見ています。
-
ステップ数:
エージェントが環境とやりとりした回数(shell ツールやファイル変更など)です。1回のやりとり(インタラクション)を 1 step として数えています。 -
コスト:
タスク完了までに必要だったLLM 推論にかかったコスト(料金)の合計です。
必要な実行ステップ数と LLM 推論コストを見ると、コンテキストファイルなし(None)が一貫して有利 でした。SWE-bench Lite と AGENTbench の両方で、すべてのモデルにおいて None が最小のステップ数とコストを記録しています(表4)。
| ベンチマーク | 条件 | Sonnet-4.5 | GPT-5.2 | GPT-5.1 M. | Qwen3-30B | ||||
| ステップ数 | コスト | ステップ数 | コスト | ステップ数 | コスト | ステップ数 | コスト | ||
| SWE-bench Lite | None | 54.4 | $1.30 | 12.5 | $0.32 | 40.9 | $0.18 | 29.7 | $0.12 |
| LLM | 57.2 | $1.51 | 12.7 | $0.43 | 45.2 | $0.22 | 32.2 | $0.13 | |
| AGENTbench | None | 40.7 | $1.15 | 12.1 | $0.38 | 40.6 | $0.18 | 31.5 | $0.13 |
| LLM | 46.5 | $1.33 | 13.1 | $0.57 | 46.9 | $0.20 | 34.2 | $0.15 | |
| Human | 45.3 | $1.30 | 13.6 | $0.54 | 46.6 | $0.19 | 32.8 | $0.15 | |
表4:かかったステップ数とコスト(原論文 Table 2 の内容を筆者側で調整)
各セルは、タスク1件あたりの平均ステップ数および平均コスト(金額は米ドル(USD)表記)を示しています。緑セルは各列の最良値を示します。全モデル、全ベンチマークで None が最良になっていることが分かります。
実験結果2:行動と原因の分析
行動分析の洞察
前節では、コンテキストファイルによって 合計のステップ数と推論コストがどう変わるか を見ました。ここではその内訳として、エージェントが実際にどのような行動を増やしたのか を実行ログから確認します。
具体的には、エージェントが環境に対して行ったツール呼び出し(例:grep / 検索、read / ファイル閲覧、write / 編集、pytest / テスト実行、依存関係ツールの実行など)の頻度と、モデル内部の推論量を確認します。
ここでは、次の2種類のログを扱います。
-
アクションログ:
どのツール呼び出しを何回行ったかを示すログです(例:readが何回、grepが何回、テストが何回、など)。 -
推論量ログ:
モデルが内部で使った reasoning tokens(推論トークン)の量です。
前節の「推論コスト」とは別の指標であり、論文ではタスクの「難しさの代理指標」として解釈しています。GPT-5 系は、難しいと感じると推論トークンを増やす性質があるとされています(参考: OpenAI Reasoning models)。
これらの詳細なログ分析から、コンテキストファイルがコーディングエージェントの行動にいくつかの変化をもたらしていることが分かりました。
コンテキストファイル利用時に観察される傾向
- 探索活動の増加: エージェントは、ファイル検索(
grep)、読み取り(read)、書き込み(write)をより多く実行しています。 - テスト行動の強化: エージェントは、
pytestなどのテスト実行コマンドをより頻繁に利用しています。 - 「難しい」と感じる傾向の増加(GPT-5 系による計測): LLM 生成コンテキストファイル条件では、推論に使われるトークン数が 14〜22% 増えました。コンテキストファイルがあると、タスクをより難しいと判断し、より多く推論する傾向があります。なお、reasoning tokens を「難しさの代理指標」とみなすのは論文側の解釈です。
- 指示の順守傾向: エージェントは、コンテキストファイル内に記載された
uvやリポジトリ固有ツールなどの推奨事項をおおむね順守しており、それらの使用回数が大幅に増えています。
このように活動量や指示順守は増える一方で、成功率の改善は一貫していません。LLM 生成では悪化傾向が見られ、Human でも改善幅は小さいため、コンテキストファイルが必ずしもより良い結果につながるわけではないことが示されています。
ドキュメントの冗長性
コンテキストファイルの効果が本当に小さいのかを確かめるために、論文ではコンテキストファイルに実際に書かれている内容にも目を向けています。
コンテキストファイルは自由に記述できますが、実際には プロジェクトに関する説明文 が中心になっているケースが多いようです。
そこで、コンテキストファイルの内容が README や docs/ など既存のドキュメントと重複しているために、かえってパフォーマンスを下げているのではないか、という問いが立てられました。
そこで、リポジトリから「ドキュメントという情報源」をまとめて外す という操作を行い、コンテキストファイル自体に書かれている内容の有効性を調査しています。
具体的に「まるごと抜く」とは、
*.mdのようなドキュメント系ファイルdocs/フォルダ- サンプルコード(example code)
を削除し「コンテキストファイルがほぼ唯一の説明書」になる状況を作ることです。その状態でエージェントを走らせてタスク成功率を見ます。
この操作の狙いは、「もしコンテキストファイルが本当にタスク成功に役立つ情報を提供しているなら、他のドキュメントを消したときに相対的な価値が上がるはずだ」という仮説を検証することです。
このようなドキュメント有無による有効性の検証は、アブレーション実験 と呼ばれます。ここでは非常に興味深い結果が観察されており、特に LLM が生成したコンテキストファイルについては、パフォーマンスが一貫して向上する傾向が報告されています。
具体的には、既存のドキュメントを削除すると、LLM によって生成されたコンテキストファイルは平均 2.7% の改善を示しています(図3)。
Claude Code(Sonnet-4.5)構成については、推論コストが非常に高額になるため、この検証実験からは除外されています。
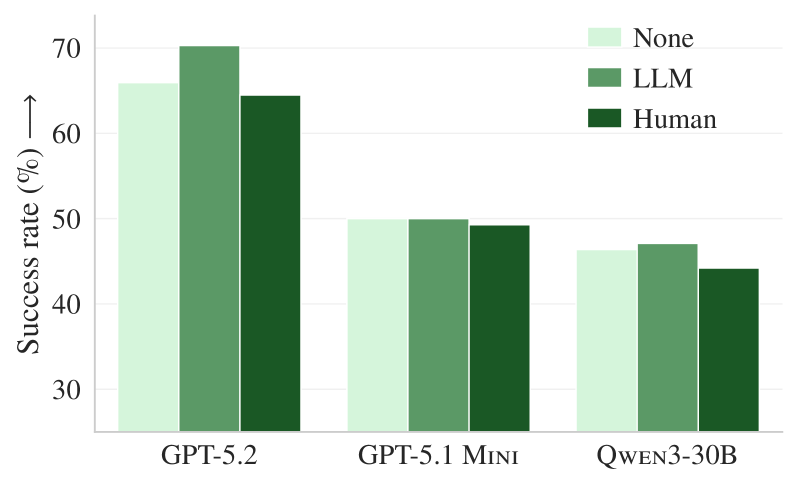
図3:アブレーション実験(原論文 Figure 5 を引用)
既存のドキュメント(README、docs/、サンプルコードなど)を除去し、AGENTS.md などのコンテキストファイルのみが主なリソースとなる場合に、エージェントのタスク成功率がどのように変化したかを示しています。
この結果から、「コンテキストファイルが有効だ」と見える場面は、不足していたドキュメントの説明をコンテキストファイルが補っていたため である可能性が示唆されます。
言い換えると、十分に文書化されたリポジトリをさらに補完するというより、ドキュメント不足を埋める役割のほうが大きい可能性があります。
/init の裏側にある生成指示の違いは効くのか?(図4)
実用面でもう一つ気になるのは、「コンテキストファイルの自動生成方法を工夫すれば、もっと良い結果が出るのではないか」という点です。
論文では、Codex 系の /init が内部的に使う生成指示と、Claude Code 系の /init が内部的に使う生成指示で作成されたコンテキストファイルとで、エージェントの成功率がどう変わるかを検証しています(図4)。
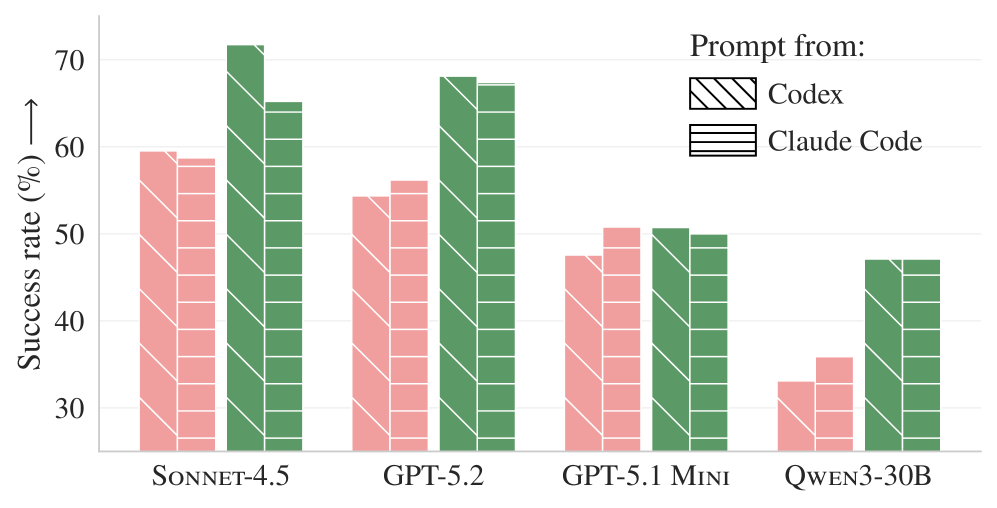
図4:プロンプトの違いによる成功率への影響(原論文 Figure 9 を引用)
同じタスクに対して、Codex 系の /init が内部的に使う生成指示と、Claude Code 系の /init が内部的に使う生成指示で作られたコンテキストファイルを比べた結果です。どちらが常に有利という傾向は見られず、/init の生成テンプレートを変えても成功率は安定して改善しませんでした。
結果として、特定のエージェントやモデルに最適化された /init の内部生成指示を使っても、タスク成功率に対する 一貫した影響は見られませんでした。
これは実用面でも重要です。少なくとも本研究の条件では、「/init の裏側にある生成テンプレートを細かく調整して、より良い AGENTS.md を作ろう」と試行錯誤しても、目に見える効果は得られにくいことを示しています。
最後に、コンテキストファイルの実用的な活用法を整理します。
実運用への活用ポイントと注意点
この研究結果をどのように受け止めればよいのでしょうか。
なお、本論文の評価は Python 中心・単発評価の条件で行われており、主指標はタスク解決率(task resolution rate)です。コード効率やセキュリティといった側面は今後の課題とされています。また、リポジトリ別に見ても、コンテキストファイルの有無が特定の単一リポジトリで有意に効いているとは言えない、とも補足されています。以下の示唆は、少なくともこの条件下での結論として読む必要があります。
ここでは、コンテキストファイルに関わる人を 現場側(日々の開発や運用を担う人)と、基盤側(エージェントやツールを設計する人)に分けて、それぞれへの示唆を整理します。
端的に言えば、この論文の条件では、現場側は 「LLM 生成に頼らず最小限に書くこと」、基盤側は 「何でも盛り込む設計を見直すこと」 が、現時点での指針になります。
| 立場 | 具体例(誰のことか) |
| 現場側 | 日々の開発、リポジトリ管理、チーム運用などでエージェントを活用する人全般 |
| 基盤側 | エージェント実行基盤、/init などの自動生成機能、リポジトリ解析、RAG(Retrieval-Augmented Generation)、プロンプトテンプレートを設計する人 |
それぞれへの具体的なポイントは次の通りです。
現場側(開発・運用)向け
- LLM によって生成されたコンテキストファイルは、当面は避けるのが無難です。 ただし、ドキュメントが少ないリポジトリでは有効になる場合もあります。
- 人が書く際は、特定のツール要件など 最小限で本当に必要なことだけ に絞るのがよいです。
- コンテキストファイルが必要かどうかは,「リポジトリにどれだけドキュメントがあるか」 を判断基準にするとよいです。
基盤側(ツール・エージェント・研究)向け
- コンテキストを最初から盛り込む設計を見直すべきです。 既存ドキュメントと重複しやすく、コスト増や成功率低下につながるためです。
- 短く、タスクに直結する情報を優先するべきです。 概要の羅列よりも、必須コマンドや制約などの最小要件のほうが有効な可能性があります。
- 不要な情報を出し分ける仕組みが重要です。 例えば、既存ドキュメントとの重複検知などが考えられます。
以上のように、コンテキストファイルを万能なものと捉えるのではなく、その役割や限界を理解したうえで、目的に応じて適切に作成、活用していくことが重要になっていきます。
おわりに
本記事では、「コンテキストファイルの有効性」をテーマにした研究を紹介しました。
開発者はそれぞれ、多様な手法や考え方を持っていると思いますが、本研究は「とにかくコンテキストを増やせば良いわけではない」という点を、定量的に示した点が重要です。どのように感じられたでしょうか。
筆者自身も Claude Code や Cursor を使う中で、この話題には試行錯誤してきました。初めて AGENTS.md や CLAUDE.md に触れたとき、「既存ドキュメントとの違いは何だろう」と感じた記憶があります。
本研究は、そうした素朴な疑問を出発点にしながら、現場の慣行を体系的に検証したものです。少なくとも現時点では、論文が示すように、必要最小限の情報に絞って運用する姿勢が有力だと言えそうです。
参照 URL
- 論文(arXiv): https://arxiv.org/abs/2602.11988
- OpenAI Reasoning models: https://platform.openai.com/docs/guides/reasoning
- Claude Code 公式ドキュメント: https://code.claude.com/docs/en/memory
- Codex 公式ドキュメント: https://developers.openai.com/codex/cli/slash-commands/#generate-agentsmd-with-init
- Qwen Code 公式ドキュメント: https://qwenlm.github.io/qwen-code-docs/en/users/features/commands/
- Gemini CLI 公式ドキュメント: https://google-gemini.github.io/gemini-cli/docs/cli/commands.html